Introduction - About Chifra
Chifra provides a solution
We think there are at least three fundamental problems with the current Ethereum ecosystem:
- It's difficult to run your own Ethereum node (not really, see below).
- Even if one runs a node, getting useful data is nearly impossible.
- All current solutions end up with a winner-take-all central database just like Google.
We discuss each of these problems below.
Ethereum nodes are difficult to run
Vitalik once called the Ethereum client software a "Big, Hairy node." No wonder people think they are hard to run.
But, with the recent arrival of dAppNode and Avado things have gotten much easier. Each of these products allows you to buy a machine, plug it in the wall, and your soon you're running your own node.
You should to this now. Buy a dAppNode, plug it in, and enjoy the benefits of running your own node. Why wait?
Useful data is hard to get
It is our strong belief that the Ethereum RPC is broken. It's missing something. An index by address.
The goal of TrueBlocks is to provide exactly that missing piece. We call our solution the Unchained Index.
The Unchained Index is created locally on your machine -- on the dAppNode. As a direct result of being local, the index has a number of amazing qualities:
- It fixes the broken node: Without an index, one cannot query the node for a "list of everything that ever happened to an address." With one, which is what the Unchained Index provides, one can make such a query. In effect this turns the node from a "really shitting database," into a perfectly fine database.
- No rate limiting: Because both your node and the Unchained Index are local and not shared with other users, there is no need for rate limiting. Your can query the local node 100s of times faster than you can an API. This has massive implications for the types of applications you can build.
- Perfectly private: All queries happen against your local node - you don't expose your IP address to anyone, nor do you expose any information about which addresses you're interested in.
- Faster queries leads to a better index:: Because we can query so much faster, we can dig MUCH deeper into the details of every block. This means our index contains more information about where an address appears on the chain. In fact, in tests against two popular Ethereum APIs, we consistently find 20-30% more appearances.
- More appearances means more accurate results: because our locally created index goes to a deeper level of detail, we can deliver to end user applications much more informative data. For example, we can fully reconcile transactions off-chain. Something not even the most expensive web-based services can do.
- Unique user experience: Because TrueBlocks is focused on the "account", the user experience is cohesive -- everything about an account is brought together in single interface. No more visiting a different website for each different dApp you interact with.
TrueBlocks ships with large suite of command line tools that allow you to make exactly the queries you want to make. One of the command line options is an API server which allows you to build blindly-fast desktop applications. We've built an example of such an application with our Account Explorer.
Avoiding winner-take-all
In it's best incarnation, TrueBlocks runs locally against your own locally running node. If you build the thing yourself, no-one can take it away from you. After the initial synchronization of your node (Erigon, for example) which may take a few weeks, you can run one of TrueBlocks' command line tools called chifra scrape. This process takes a few days.
To ease the burden of having to create the Unchained Index yourself, you may download it from IPFS using chifra init. Putting this data on IPFS has the very interesting consequence of sharing it. This makes it impossible for us (or anyone) to become the "holder of all data" which eventually leads to winner-take-all like Google. We want to purposefully avoid that.
This whole process is better explained here.
Unchained Index provides huge advantages
Besides the philosophical benefits, TrueBlocks is straight up more performant.
- Querying straight from your hard drive is 100s of times faster than an API.
- A local binary cache makes subsequent queries nearly instantaneous.
- Avoiding a full extraction of the data from the node results in much lower hardware requirements: from terabytes to gigabytes.
- Bloom filters further reduce storage overhead and greatly lessen the search time for particular addresses.
- Articulation resolves the transactional detail at the byte level, turning byte streams into human-readable data.
- The data can be exported into many formats: JSON, CSV, TSV, OFX, etc.
TrueBlocks performs so well because the design data first. We are lifelong hackers, and we agree with Linus Torvalds when he said:
In fact, I'm a huge proponent of designing your code around the data, rather than the other way around.
More words
We've got more words for you. This blog post covers these topics in much more detail.
About the Name
Where does the name chifra come from?
About TrueBlocks
TrueBlocks provides a solution
We think there are at least three fundamental problems with the current Ethereum ecosystem:
- It's difficult to run your own Ethereum node (not really, see below).
- Even if one runs a node, getting useful data is nearly impossible.
- All current solutions end up with a winner-take-all central database just like Google.
We discuss each of these problems below.
Ethereum nodes are difficult to run
Vitalik once called the Ethereum client software a "Big, Hairy node." No wonder people think they are hard to run.
But, with the recent arrival of dAppNode and Avado things have gotten much easier. Each of these products allows you to buy a machine, plug it in the wall, and your soon you're running your own node.
You should to this now. Buy a dAppNode, plug it in, and enjoy the benefits of running your own node. Why wait?
Useful data is hard to get
It is our strong belief that the Ethereum RPC is broken. It's missing something. An index by address.
The goal of TrueBlocks is to provide exactly that missing piece. We call our solution the Unchained Index.
The Unchained Index is created locally on your machine -- on the dAppNode. As a direct result of being local, the index has a number of amazing qualities:
- It fixes the broken node: Without an index, one cannot query the node for a "list of everything that ever happened to an address." With one, which is what the Unchained Index provides, one can make such a query. In effect this turns the node from a "really shitting database," into a perfectly fine database.
- No rate limiting: Because both your node and the Unchained Index are local and not shared with other users, there is no need for rate limiting. Your can query the local node 100s of times faster than you can an API. This has massive implications for the types of applications you can build.
- Perfectly private: All queries happen against your local node - you don't expose your IP address to anyone, nor do you expose any information about which addresses you're interested in.
- Faster queries leads to a better index:: Because we can query so much faster, we can dig MUCH deeper into the details of every block. This means our index contains more information about where an address appears on the chain. In fact, in tests against two popular Ethereum APIs, we consistently find 20-30% more appearances.
- More appearances means more accurate results: because our locally created index goes to a deeper level of detail, we can deliver to end user applications much more informative data. For example, we can fully reconcile transactions off-chain. Something not even the most expensive web-based services can do.
- Unique user experience: Because TrueBlocks is focused on the "account", the user experience is cohesive -- everything about an account is brought together in single interface. No more visiting a different website for each different dApp you interact with.
TrueBlocks ships with large suite of command line tools that allow you to make exactly the queries you want to make. One of the command line options is an API server which allows you to build blindly-fast desktop applications. We've built an example of such an application with our Account Explorer.
Avoiding winner-take-all
In it's best incarnation, TrueBlocks runs locally against your own locally running node. If you build the thing yourself, no-one can take it away from you. After the initial synchronization of your node (Erigon, for example) which may take a few weeks, you can run one of TrueBlocks' command line tools called chifra scrape. This process takes a few days.
To ease the burden of having to create the Unchained Index yourself, you may download it from IPFS using chifra init. Putting this data on IPFS has the very interesting consequence of sharing it. This makes it impossible for us (or anyone) to become the "holder of all data" which eventually leads to winner-take-all like Google. We want to purposefully avoid that.
This whole process is better explained here.
Unchained Index provides huge advantages
Besides the philosophical benefits, TrueBlocks is straight up more performant.
- Querying straight from your hard drive is 100s of times faster than an API.
- A local binary cache makes subsequent queries nearly instantaneous.
- Avoiding a full extraction of the data from the node results in much lower hardware requirements: from terabytes to gigabytes.
- Bloom filters further reduce storage overhead and greatly lessen the search time for particular addresses.
- Articulation resolves the transactional detail at the byte level, turning byte streams into human-readable data.
- The data can be exported into many formats: JSON, CSV, TSV, OFX, etc.
TrueBlocks performs so well because the design data first. We are lifelong hackers, and we agree with Linus Torvalds when he said:
In fact, I'm a huge proponent of designing your code around the data, rather than the other way around.
More words
We've got more words for you. This blog post covers these topics in much more detail.
Do I need a node?
And if you are running your own node, TrueBlocks works best with Erigon.
Why having a node is the best option
Some benefits of TrueBlocks can be realized only when a user has their own node. Having a node lets users:
- Limit queries to the node on their machine
- Use the node to build a local index
- Query data directly from the top of the chain
Setting up a node is not as hard as many people think, but it does require two TBs of storage and some good hardware.
If you want to build your own index, plan for a few days and run chifra scrape.
Before doing so, you probably want to read the relevant section in the
"How Can I Get the Index" article,
and the scrape command documentation.
Fortunately, TrueBlocks also publishes the index on the IPFS, which lets you access it locally without running a node.
Without a node, you can download the index from the IPFS
Downloading the IPFS manifest is a good option for many users:
- The initial time to get started is much faster
- The index occupies only the space you need, (between 1 and 80GB)
- You can verify its correctness with the TrueBlocks source code
- You can own the index on your local machine (though you still need to query remote RPCs for transaction data).
There are two commands to download the index, chifra init and chifra pins.
The pros and cons of each approach are outlined in the
"How Can I Get the Index?" article.
Drawbacks of using the IPFS manifest
The drawbacks of using the IPFS manifest are the opposite of the benefits of building an index from your own node:
- You still must query transaction data from remote RPCs
- You must trust the data TrueBlocks publishes (though you can verify the build)
- You can only query up to the last time TrueBlocks published the manifest
Multi chain
Accessing multiple chains
As of version 0.25.0-alpha, TrueBlocks supports accessing data from any EVM-based blockchain that supports the requisite RPC endpoints. This includes most blockchains we know of.
In order to use this new feature, you have to do almost nothing. All you have to do is add --chain <chainname> to any chifra command (except one or two as detailed below).
For example:
| Command | Notes |
|---|---|
| chifra blocks 12 | Default chain is mainnet |
| chifra blocks 12 --chain mainnet | Same as default |
| chifra blocks 12 --chain gnosis | Block 12 from gnosis chain |
How can this possibly work?
To be perfectly honest, it can't -- without you.
You must be running your own RPC endpoints. We built TrueBlocks in this way on purpose -- TrueBlocks is not a service. It's a locally running tool. We did this because doing otherwise promotes a world of highly centralized solutions--something we are trying very hard to avoid.
Once you do start to run your own node software, you will be very glad you did. While you can use publicly available endpoints such as Infura, you will find that you will almost certainly be rate-limited. This is not true if you run your own node.
Support for default chains
Notwithstanding the above, we've provided default configurations for the following eight (8) EVM compatible chains:
mainnet, rinkeby, ropsten, goerli, kovan,
gnosis, optimism, polygon
In each case (except mainnet) we point to public RPC endpoints. It is likely that you will be rate-limited if you use these options. Providing your own endpoints is much preferred.
The Default Chain
A new configuration item has been added to the trueBlocks.toml file under the [settings] section. That item is called defaultChain. The initial value is mainnet. After installing version 0.25.0-alpha any chifra command that is run without the --chain option will default to defaultChain. You may modify this and subsequently remove the --chain option if you wish to default to a different chain.
Adding your own chain
To configure a chain or add a new one, you must edit an entry for the chains array in the trueBlocks.toml file.
Once added, you may use your new chain entry by naming it to the --chain option:
chifra <cmd> <options> --chain <chain-name>
Below is one of the pre-configured sections for Ethereum Mainnet. Following that is a description of fields making up a chain configuration. Note that the section header of the chain must start with chains. and becomes the name of the chain.
[chains.mainnet]
chainId = "1"
rpcProvider = "http://localhost:8545"
remoteExplorer = "https://etherscan.io"
apiProvider = "http://localhost:8080"
localExplorer = "http://localhost:1234"
pinGateway = "https://ipfs.unchainedindex.io/ipfs/"
symbol = "ETH"
Your entry must contain the following fields (some of which are optional):
| Field Name | required | Description |
|---|---|---|
| chainId | yes | The chain id as returned by eth_chainId |
| rpcProvider | yes | The RPC provider for the chain. Highly preferred this is local and dedicated. |
| remoteExplorer | A remote blockchain explorer for the chain (such as EtherScan). Used by chifra explore | |
| pinGateway | Only needed if you are running chifra scrape --pin. Note you will need your own Pinata endpoint. |
The following three fields are only needed if you're also running the TrueBlocks Explorer:
| Field Name | required | Description |
|---|---|---|
| apiProvider | The URL given by chifra serve and where the explorer will get its data. | |
| localExplorer | The URL of the local explorer application. Where chifra explore --local will open. | |
| symbol | The symbol of the native token on the chain in question. ETH for mainnet, xDAI for gnosis for example. |
What Doesn't Work?
There are two things that currently do not work with Multi-Chain:
-
The command
chifra initonly works with Ethereum Mainnet. While we will never provide an index for every chain (we must rely on our user base to do that and hopefully share it), we will, in the future be supporting some chains, notably the gnosis chain. -
Pricing using UniSwap only works on the mainnet. In the future, once more standardization appears relative to pricing on multiple chains, this choice will be revisited.
Design philosophy
The three commandments
-
Let users query this data without asking third-parties for permission.
If you can access blockchain data only through a third party (e.g. a cloud provider), is the data really decentralized?
-
Provide accurate access, to underived, consented-to, pure immutable data.
If the blockchain data is not accurate, what good is the blockchain?
-
Perform well on small machines
If an application requires web-scale computer infrastructure, does it really support decentralization?
How TrueBlocks prioritizes design features
No application can do all things. All design decisions involve tradeoffs. TrueBlocks tries to make trade off consciously, so that we always make the application best serve our core values.
Core design values
These core design features are imperative. They underlie every single commit made to the TrueBlocks code base.
| Core design values | What they mean in practice matter |
|---|---|
| Decentralization | No one should have to rely on anyone other than themselves for data. This including users who want data at the very end of the data journey |
| Performance | TrueBlocks should be fast on small machines, and provide options for minimal disc footprints |
| Preserves integrity of data | Blockchain data is mutually-agreed upon and consented-to. Don't tamper with it. |
Very important values
These values are particularly important. They are naturally necessary to achieving the core design features.
| Very important values | What they mean in practice |
|---|---|
| Transparency | Every person gets permissionless access to all the data they want; the application should be open source, letting users verify the data |
| Reproducibility | Required for transparency and decentralization |
| Stability | It should run forever with zero downtime |
Important values
These values are important, and TrueBlocks tries to maximize these values wherever possible. However, if we have to make a tradeoff, these values come after the core values.
| Important values | What they mean in practice |
|---|---|
| Robustness | App should work forever without needing to be futzed with |
| Approachability | Easy to understand how it works; easy to understand how to get started |
| Simplicity | Related to Approachability |
| Extensibility | Others should be able to add to it |
| Maintainability | Ideally requires no maintenance |
| Debuggability | An internal concern |
Not priorities
While TrueBlocks does not try to sacrifice these values, they are not core concerns.
| Not a priority | Why these values aren't emphasized |
|---|---|
| Compatibility | Depends on programming languages that we use, so not a concern |
| Composability | Not really a concern |
| Expressiveness | Not a concern, readable commands more important |
| Interoperability | Only care about data being platform-independent. Production of the index needs to create something that is useful outside of TrueBlocks |
| Mensurability | For internal use only, so less of a concern |
| Portability | Depends on programming language, so not a concern |
| Safety | Not really. Consented to data is safe. |
| Security | Not really. Out of our code's purview other than basic software security. We hold no special data: our data is consented-to data. Reproducible, consented-to data is reproducibly safe. The app runs on local machines. If the local machine is compromised, TrueBlocks is not the user's biggest security concern. |
| Thoroughness | The application should do one thing perfectly -- reconciliations |
This ranking of values was inspired by a talk given by Bryan Cantrill in 2018.
Mantras for decentralized data
Because "commandments" sounds authoritarian and Abrahamic, we also keep an ongoing list of mantras.
If repeated endlessly, they will eventually sink in:
- All the data, for all the people, all the time, but no data if the user doesn’t want it
- Use only consented-to data…
- If you can’t do that, use only data derived directly from consented-to data
- If you can’t do that, find a way to force the data provider to prove their data
- The paradigm has shifted, embrace it - the server is now called localhost
- Break yourself out of the browser. There’s a big wide desktop out there
- It’s easier to scale up than to scale down - decentralize first
- Most users care only about themselves and maybe a few smart contracts
- Some users, but not all, care about everything
- Everyone needs to do accounting and pay taxes
- The node can, and should be, be improved
Installation
Prologue
Unchained Index
| If you want... | and you don't mind... | then use... |
|---|---|---|
| to minimize the size of the data stored locally and you want to get started faster... | slower first-time queries on new addresses, an index that's slightly behind the head of the chain, an index created by someone else... | chifra init |
| to maximize the speed of first-time queries for new addresses... | longer initial setup time, ~70 GB of local storage, an index that's slightly behind the head of the chain, an index created by someone else... | chifra init --all |
| have a locally-running node and wish to build the index yourself... | two to three days setup time and running your own local node (such as dAppnode).... | chifra scrape |
Getting the index without running a node
If you're not running your own node (or you don't feel like waiting), you can download all or part of a pre-built index from IPFS.
To do this, you have two options:
- run
chifra initto download only the Bloom filters. Then, as you query individual addresses, TrueBlocks will download the much-larger index chunks (faster now, slower later) - run
chifra init --allto download both the Bloom filters and the index chunks all at once (slower now, faster later)
Use chifra init to get a subset of the data
To get only the Bloom filters, run chifra init.
If you do this, you will have to periodically re-run the command to update your index. (Read about the finding the latest manifest).
For more information, see the chifra init command documentation.
Initial set up time: chifra init takes only about a half an hour on a machine with a good connection. (We've had report from some users that it takes much longer, but we suspect they are on slow machines.) We highly prefer you have a capable machine.
Storage use: In this scenario, since you only download the Bloom filters, the space required is about 1GB. Subsequently, as you download individual chunk, each chunk occupies about 25MB.
The number of index chunks you download depends entirely on the addresses you query. Of course, if you query a lightly used address, very few chunks will be downloaded. However, if you query are heavily used address, such as UniSwap, nearly every chunk will be downloaded. This is by design. In the later case, you would probably be better off using chifra init --all to begin with.
- For typical addresses (e.g. personal accounts), storage is somewhere between 50 to 500 MB
- For more active addresses, storage may be as much as 1 or 2 GB
- For very popular smart contracts, the storage requirement may be as high as 50 GB
How it works
When you run chifra init, TrueBlocks downloads a set of Bloom filters from the latest published manifest to your local machine. Subsequently, when you want to explore an address history, e.g. with the command chifra export <address>, TrueBlocks:
- Scans the Bloom filters for potential matches and if there's a hit, downloads the corresponding index chunks.
- Returns the set of
appearancesfor the address as pairs of<block number>and<transaction_id>. (This permits direct queries for exact details of desired transaction histories). - Given the list of
appearances, TrueBlocks pulls the full transactional history of the account from any (remote or local) RPC endpoint. - During the query, you may instruct TrueBlocks to cache the response locally, making future queries for this same address nearly instantaneous.
Use chifra init --all to get the entirety of the index
To get the entirety of the appearance index, run chifra init --all.
If you use this command and don't run chifra scrape, you will have to update the index periodically by running the command again. (Read about the finding the latest manifest).
For detailed instructions, see the chifra pins documentation.
Initial set up time: Somewhere between six and ten hours depending on the speed of your connection.
Storage use: About 60GB-80GB
How it works
The initialization is very similar to the init process described in the previous section.
However, while chifra init downloads only the Bloom filters, downloading the index chunks only after a user queries for an address, chifra init --all downloads all index chunks up front.
While this process takes much longer (perhaps hours), when you query a particular address in the future, TrueBlocks no longer has to download anything.
Therefore, the query is significantly faster.
In other words, the first time you run chifra export <transaction>, the process is much faster than it is if you initialize with chifra init alone.
As is true of the previous methods, if you enable caching, subsequent queries for the same address return almost instantly.
Use chifra scrape to build your own index
👉 Note: If you don't have a node with tracing or archiving,
scrapeexits by default. You can still use scrape, but you need to open your config and disable these checks
To build your own index without any downloading, run chifra scrape.
For detailed instructions, see the chifra scrape command documentation.
Initial set up time: This method requires a locally-running tracing / archive node such as dAppNode running Erigon. Early users have reported 2-4 days to build the index from scratch. (You may wish to run chifra scrape in an application like tmux, so you can close the terminal window while it builds.)
Storage use: About 60GB.
How it works:
The end result of chifa scrape is the same as the end result of chifra init --all. However, the process is crucially different: rather than downloading the index that we publish (that is, trusting us), chifra scrape builds the index on your local machine connecting only with your local-running RPC endpoint, which means if you trust your own setup, you can trust the data.
(One note: It's possible to run against any RPC endpoint -- remote or local -- but because the TrueBlocks scraper hits the node continually and very aggressively, you will probably get rate-limited against a shared RPC server such as Infura.)
A good explanation of this whole process requires a long form article. For now, the curious may look at the best documentation available, the src directory of the source code.
One final note on building / making the index
You can, if you wish, mix and match the above methods.
For example, you can initially download only the Bloom filters with chifra init and then start up chifra scrape in the background. This would allow you to get started quickly but stay up to the front of the chain. Of course, as with everything, there's a tradeoff. You will be storing a few MB every time a new chunk is created (about three times a day). In return, it's way faster to query and the index stay up to the chain.
Alternatively, you may choose to scrape (i.e. build) the index yourself and share it with others by pinning it on IPFS. In this case, you're being a good citizen and making the whole ecosystem better off because you're sharing you index.
You can download the index (either with chifra init or chifra init --all) and pin that data (with the --pin_locally flag) as a way to share with the community, and then turn on the scraper. All options are available as a way to maximize the usefulness of the tool.
Supplementary: how can I see when the manifest was last published?
To view the latest manifest published by TrueBlocks (note that there may be other publishers), pass our publisher id: 0xf503017d7baf7fbc0fff7492b751025c6a78179b and the string mainnet to the manifestHashMap() method of the UnchainedIndex_V2 contract at https://etherscan.io/address/0x0c316b7042b419d07d343f2f4f5bd54ff731183d#readContract. This will return the LATEST_IPFS_HASH of the manifest. To fetch the manifest, use an IPFS client and ipfs get <LATEST_IPFS_HASH> or a gateway (such as the one TrueBlocks maintains) https://ipfs.unchainedindex.io/ipfs/LATEST_IPFS_HASH.
Edit the resulting file to see the latest published data.
Alternatively, you may always use chifra chunks manifest to see where the latest published index is at.
Install core
These instructions assume you can navigate the command line and edit configuration files. If you need help with a particular step, see the installation's troubleshooting section.
Installation
-
Open a terminal window.
-
Type
go version. If Go is not installed or less than Go Version 1.23, install the latest version of Go -
Install or upgrade the build dependencies: git, cmake, ninja, curl, python, clang-format, jq
-
Clone the repo and compile the executable:
git clone --depth 1 --no-single-branch --recurse-submodules --branch develop https://github.com/TrueBlocks/trueblocks-core
cd trueblocks-core
mkdir build && cd build
../scripts/go-work-sync.sh
cmake ../src
make
-
Switch to the
masterbranch if you want a more stable version. -
The build may be faster with
make -j <nproc>. -
Add
./trueblocks-core/binto your shell's $PATH. Check Google if you don't know what this means. -
Type
chifra config --paths. This will produce a display similar to the following (ignore any errors). Note the$CONFIGpaths.
chifra config --paths:
Config: $HOME/Library/Application Support/TrueBlocks/
Cache : $HOME/Library/Application Support/TrueBlocks/cache/mainnet
Index : $HOME/Library/Application Support/TrueBlocks/unchained/mainnet
- Next, edit a configuration file called
$CONFIG/trueBlocks.toml. Edit this file and locate the[chains.mainnet]section. Add a valid RPC endpoint. If you don't know what this means, search Google.
[chains.mainnet]
...
rpcProvider = "http://localhost:8545"
...
- If you wish to use the
--articulatefeature (you probably do), add an API key to the following section:
[keys.etherscan]
...
apiKey = "<your Etherscan api key>" # optional
...
Testing the install
If you've installed things properly, you should be able to now run the following command, which should return this data:
chifra blocks 12
You should get results similar to these:
{
"data": [
{
"gasLimit": 5000,
"gasUsed": 0,
"hash": "0xc63f666315fa1eae17e354fab532aeeecf549be93e358737d0648f50d57083a0",
"blockNumber": 12,
"parentHash": "0x3f5e756c3efcb93099361b7ddd0dabfeaa592439437c1c836e443ccb81e93242",
"miner": "0x0193d941b50d91be6567c7ee1c0fe7af498b4137",
"difficulty": 17179844608,
"finalized": true,
"timestamp": 1438270144,
"baseFeePerGas": 0
}
]
}
- Assuming the above works, your system is properly installed. If not, see the TroubleShooting section.
More information
There's a lot left to learn. Have fun:
- Using the Unchained Index
- Explore some coding examples
- View data science recipes
- Use the explorer application
Install SDKs
First, make sure that you have the chifra-core backend up and running,
then run the application from a clone of the explorer repo.
Before you begin
☑ Set up the trueblocks backend using the chifra installation instructions
☑ In a terminal window, run the command chifra serve
Install
Keep the chifra serve process running.
Then, in a new terminal, run these commands:
- git clone git@github.com:TrueBlocks/trueblocks-explorer.git
- cd trueblocks-explorer
- cp .env.example .env
- yarn
- yarn develop
Open your browser, and access the app from localhost:1234.
Install explorer
First, make sure that you have the chifra-core backend up and running,
then run the application from a clone of the explorer repo.
Before you begin
☑ Set up the trueblocks backend using the chifra installation instructions
☑ In a terminal window, run the command chifra serve
Install
Keep the chifra serve process running.
Then, in a new terminal, run these commands:
- git clone git@github.com:TrueBlocks/trueblocks-explorer.git
- cd trueblocks-explorer
- cp .env.example .env
- yarn
- yarn develop
Open your browser, and access the app from localhost:1234.
Install Docker
First, make sure that you have the chifra-core backend up and running,
then run the application from a clone of the explorer repo.
Before you begin
☑ Set up the trueblocks backend using the chifra installation instructions
☑ In a terminal window, run the command chifra serve
Install
Keep the chifra serve process running.
Then, in a new terminal, run these commands:
- git clone git@github.com:TrueBlocks/trueblocks-explorer.git
- cd trueblocks-explorer
- cp .env.example .env
- yarn
- yarn develop
Open your browser, and access the app from localhost:1234.
Install Docker
First, make sure that you have the chifra-core backend up and running,
then run the application from a clone of the explorer repo.
Before you begin
☑ Set up the trueblocks backend using the chifra installation instructions
☑ In a terminal window, run the command chifra serve
Install
Keep the chifra serve process running.
Then, in a new terminal, run these commands:
- git clone git@github.com:TrueBlocks/trueblocks-explorer.git
- cd trueblocks-explorer
- cp .env.example .env
- yarn
- yarn develop
Open your browser, and access the app from localhost:1234.
Troubleshooting
This section lists solutions to problems some users have run into with the installation. If you continue to have trouble, create an issue, or ask us on discord.
Dependencies
Installing go
How do I check my Go version?
Run this command
go version
TrueBlocks needs version 1.16.x or later. If you to install or update Go, see here.
Installing build tools
How do I install the build packages for my system?
Linux: sudo apt install build-essential git cmake ninja-build python3 python3-dev libcurl4-openssl-dev clang-format jq
Mac: brew install cmake ninja git clang-format jq
Building TrueBlocks
Did it work?
How do I know if compilation worked?
From the ./trueblocks-core/build folder, test your installation with this command:
../bin/chifra version
You should get a version string similar to this:
trueBlocks GHC-TrueBlocks//0.9.0-alpha-409aa9388-20210503
If nothing outputs, your installation or the build has failed. Try repeating the installation instructions. If it still fails, make an issue or join our discord.
Exporting your PATH
How do I export my PATH?
chifra only works if its underlying tools are found in your $PATH.
To find the full path, run this from the top of the trueblocks-core directory.
cd bin && pwd && cd -
Add the result of that command to your shell’s $PATH.
How you do that depends on your system.
In Bash, you're probably going to put something like this in your .bashrc:
export PATH=${PATH}:</path/to/trueblocks-core/directory>/bin
If you are confused, a Google search may be in order…
Number of cores
How many cores can I use to make TrueBlocks?
When you run make, you can speed up the build by parallelizing with
make -j <ncores>
Where <ncores> represents the number of cores to devote to the job.
How many cores can you use? That depends on many factors. A handy tool is nproc,
which identifies the machine's number of available processing units.
If you have nproc installed, you can safely parallelize the build with this command
make -j `nproc`
Configuration
Where?
Where are the configuration files?
Where your configuration folder is depends on your operating system and environment.
- If
XDG_CONFIG_HOMEis set, your configuration is there - Otherwise, on Linux:
~/.local/share/trueblocks - Otherwise, on Mac:
~/Library/Application Support/TrueBlocks - Otherwise, you're out of luck--we only support Linux and Mac
The primary or base configuration file (trueBlocks.toml) must exist at one
of the above locations for chifra to work.
With the recent addition of support for multi-chain, there has arisen the need
for per-chain configuration as well (for example, values such as rpcProvider or
remoteExplorer are unique per chain).
This issue is discussed here TODO: PLACE_HOLDER.
RPC endpoint
How do I specify an RPC endpoint?
By default, TrueBlocks looks for the RPC at http://localhost:8545/.
If you are using a remote RPC such as Infura or your own local RPC at a different port, you will need to modify that value.
As is true of all configuration values, you coudl use an environment
variable as described above, but you may also edit trueBlocks.toml.
The format of that file is documented TODO: PLACE_HOLDER.
API keys
How do I add a EtherScan key?
Some small part of TrueBlocks requires an EtherScan API key. In particular
this is the --articulate option. We are working
hard to remove this centralized dependency, but in the mean time you
may get a warning of a missing key.
Here’s an example of a remote RPC for Infura and an EtherScan API key. Warning: see the note below
[settings]
default_chain=mainnet
etherscan_key = "<key_value>"
[mainnet]
rpcProvider = "https://mainnet.infura.io/v3/<key_value>"
Note: Until mutli-chain is fully supported, put the rpcProvider value
in the [settings] group.
Note: The EtherScan key is not per-chain.
Do I need the index?
Why do I need the index of appearances?
If you're only querying basic block or transaction data, you don't really need the index of appearances.
However, most of our users with to explore the entire history of their own addresses. If you wish to do that, you will need the index.
There are multiple options for getting the index, which the How Can I Get the Index? article covers in more detail.
No matter which method you use, downloading or creating the index will take somewhere between a few minutes and a day or two. So you might want to play around with some chifra blockchain commands first.
Archive nodes
What if my node doesn't have tracing or archiving? {#no-tracing}
If the node you're running does not support OpenEthereum style tracing or it is not an archive node, you may get an error telling you such.
Something like
--accounting requires historical balances. The RPC server does not have them. Quitting...
You may disable this warning by editing a configuration file. Find the file
called blockScrape.toml in your configuration folder (in a multi-chain environment
this will be in the chain-specific config file, otherwise at the top level).
Add the following setting to the file (which you may create if it doesn't exist):
[requires]
tracing = false
archive = false
FAQ
{{< toc >}}
Usage
-- Can I get my balance for a given token?
Yes. There is. In fact, this is one of TrueBlocks' most important features. Simply do chifra export --statements <address(es)> or query the API serve with http://localhost:8080/export?addr=<address>&statements.
Note that chifra export has many, many other options which produce similarly-informative data such as --logs, --appearances, --neighbors, --accounting, and so on. See the entire help file with chifra export --help.
-- Token four-bytes come in two flavors. How do you handle that?
The purpose of chifra export is to extract all transactions necessary to do 18-decimal-place-accurate accounting for a given address (or addresses).
If we encounter such as case (where there is a conflict in the four-byte or event topic), we pull that transaction as we would any other, but...when we query for the accounting (i.e. we query the smart contract for ERC20 balances), we get either an errored response in the conflicting case. This "mistaken ERC20 transfer" will have no value. The transaction may appear in the list of all transactions, but it will have no effect on the accounting.
In other words, regular old-fashioned, off-chain double-entry accounting will comes to the rescue. This is by design because as you point out, it's not possible to be perfect using purely on-chain data.
-- Can I use my own ABI for the --articulate option?
The chifra abis routine will try to find the ABI in the local folder by looking for <address>.json, although you may specify the --sol option and feed it the solidity code. Failing that, chifra looks to EtherScan for the ABI. Failing that it falls back to a collection of about 2,800 'known' signatures from EIP standards (ERC20, etc.) and some popular smart contracts ENS, Zephlin, etc.
-- I want to make a list of all tokens I own and their historical balances. How do?
An article on why this is hard: https://trueblocks.io/blog/how-many-erc20-tokens-do-you-have/
A first draft of an article on how to accomplish this: https://github.com/TrueBlocks/tokenomics/blob/main/explorations/accounting-03/notes.md
-- How does chifra handle multiple accounts?
I will try to answer this myself by going through the code, but how does chifra handle multiple accounts? Say I have 10 addresses that I view as a single bundle. One wallet may buy a token and send it to another wallet that ultimately sells it. In this context, there was a buy and a sell and it doesn’t really matter which wallet it came from. Can chifra handle this situation to produce the financial statements and double entry accounting at the “bundle” level instead of the address level? tjayrush | TrueBlocks.io — Today at 11:21 AM Hard question to answer, but I'll try. (I might add this to the FAQ). tjayrush | TrueBlocks.io — Today at 11:31 AM Start at the beginnging. Everything other than ETH is an ERC20 token, so as long as they are compliant, we should be able to search for Transfer events to do perfect accounting. Unfortunately, that is not the case. Why?
Some (many?) smart contracts transfer ownership of tokens without generating an event. Most notable example of this is minting which isn't even a requirement of an ERC20 token. (Don't believe that, read the spec. It says ERC20 tokens SHOULD generate an event on mint, but they don't have to.)
Second, some ERC20 smart contracts report "accumulated earnings" based on a time span. So even though the contract's underlying ledger says a person owns X tokens, if he's held those tokens for Y days, it might report X + (rate of return * Y). And, there's no event generated each time the "balance" changes.
All that is just pre-amble, but the point is that every asset is an ERC20 token underneath it all.
chifra export --accounting --statements takes any number of addresses on the command line (use --file option to overcome command line limits). So, you can collect together a list of addresses, and run that command. Each individual address with only see tokens appear and disappear (through whatever mechanism). If one sends tokens out of one address and into another, that "transfer" will cancel out. + on one side, minus on the other. There's kind of nothing you have to do about it.
Summary: make a list of all addresses and it will just take care of itself.
Note this only works for non-CEX addresses which must be handled separately and which we don't yet have a solution.
Running a Node
-- Why would anyone want to run a local Ethereum node?
It's faster, cheaper, uncensorable, and private.
Faster: You can hit your own RPC endpoints as fast as you could possible want. No rate limiting. It's surprsing how important this is. It transforms a "difficult-to-use node" into a perfectly fine data server.
Cheaper: Over time, it's way, way cheaper to run your own infrastructure. There's only a single initial capital outlay. Plus -- you don't need a huge memory machine. Once the node and our scraper are caught up to the front of the chain, there's only a single block at every so many seconds. This is easily handled for both the local node and TrueBlocks. More memory is better, of course, but is also not the main bottleneck. (In fact, there are no bottlenecks--they system is mostly waiting for new blocks from the network.)
In the past, large disc space requirements used to be a problem -- especially with an archive node such as OpenEthereum (or Geth), each of which required 10-12 TB. Erigon requires only 2-3TB for the exact same data. You need at least a 4TB hard drive, but these are increasing more available.
One could, if they wished, used "node-as-a-service" such as Infura or QuickNode, but the monthly cost is high -- up to $250.00 for a base-layer (i.e. no tracing) archive node access with 'dedicated servers' going up from there. The former suffers from the 'rate-limiting' problem, and the later is probably way more expensive. A local machine quickly pays for itself.
Uncensorable / private: You're running your own servers inside your own building. If someone is either censoring your data or invading your privacy, you have only yourself to blame. These two aspects of the data access should be your responsibility, not a third-party provider.
Our recommendation is definitely a local machine running Erigon, with TrueBlocks installed on the same machine. An excellent option is dAppNode.
-- The docs say you require Erigon. Is that true?
There's four reasons we suggest Erigon (the last is a deal-breaker).
- Erigon is MUCH faster syncing -- two weeks vs many months for archive node
- Erigon takes up MUCH less disc space - 2 TB vs. 12 TB for an archive node
- Erigon's RPC is faster
- Erigon natively supports the trace_ namespace. Geth supports it but only through a JavaScript emulator -- tracing is literally unusable in Geth. TrueBlocks needs tracing.
Item 1, is not that bad -- if you have the time to wait.
Item 3, is dependent on which RPC endpoints you use -- particularly tracing.
Item 2 matters immensely to us since we are so focused on running on small, decentralized machines and makes all other nodes not viable.
Item 4 is a deal breaker. Without traces, we would have to re-write the internals of our scraper. Plus, without traces, the "quality" or "completeness" of our solution is seriously compromised. We could index just events (like The Graph), but that will never allow you to reconcile (in an accounting sense) which is one of our priorities as well.
If you're running against a non-archive Geth node (or any other node), then TrueBlocks will not work very well. After all, TrueBlocks' entire purpose is to study the transactional histories of an address. Non-archive nodes do not provide any historical transactional data.
If you're running against an archive Geth node (or other node software that does not support Parity traces), again, things won't work very well. TrueBlocks requires traces to dig fully into an account's transactional history. This is not a choice of TrueBlocks, it's a choice if the node software. Without Parity traces, the node simply can't keep up with the requirement to produce an accurate index.
If you're running against node software that is both an archive node and supports Parity tracing in a performant way (such as Erigon and Nethermind), then you'll run into one more problem. Disc space usage. Geth and Nethermind (and the old OpenEthereum) take up more than 10TB of disc space if you're running an archive node. Erigon takes up 2TB. Five times less.
Upshot: Erigon is our greatly preferred node software. Geth is basically unsupported by TrueBlocks. Nethermind is possible, but only if you have a very large hard drive.
Building the Unchained Index
-- What do the terms finalized, staging, ripe, and unripe mean?
Run this command: chifra config. You will see output similar to this:
2022/10/24 07:21:20 Client: erigon/2022.09.3/linux-amd64/go1.18.2 (archive, tracing)
2022/10/24 07:21:20 TrueBlocks: GHC-TrueBlocks//0.41.0-beta-20b34d9e0-20221024 (eskey, pinkey)
2022/10/24 07:21:20 RPC Provider: http://localhost:23456 - mainnet (1,1)
2022/10/24 07:21:20 Config Path: <local path>
2022/10/24 07:21:20 Cache Path: <local path>
2022/10/24 07:21:20 Index Path: <local path>
2022/10/24 07:21:20 Progress: 15817943, 15817229, 15817806, 15817941, ts: 15817942
Notice the last line labeled "progess". What do these numbers mean? They are, in order, latest, finalized, staged, ripe, and timestamp. (unripe is not included.)
Here's what these numbers mean:
| block | meaning | distance from head | configurable | will be revisited |
|---|---|---|---|---|
| latest | The latest block on the chain. Same as `eth_getBlockByNumber('latest'). | 0 blocks | - | - |
| finalized | The last block that has been consilidated into a "chunk". (i.e. an index portion). | depends | yes | no |
| staging | The latest block "on the stage". (i.e. awaiting inclusion in the next chunk). | depends | yes | no |
| ripe | Blocks that have been scraped, but not yet staged. | 28 blocks | yes | no |
| unripe | Blocks that are "too close to the head" to be reliable. | 0 blocks | no | yes |
| timestamp | The latest scraped timestamp (used for debugging). | n/a | - | no |
For a much better explaination of these numbers (and more generally the scraper), please see the TrueBlocks Spec.
-- I'm getting an error message: current file does not sequentially follow previous file. What do?
When using chifra scrape you may get the above message. What this means is at least one empty block was encountered during a single pass. When I say "empty", I mean that the block did not even contain a miner address. Our scraper assumes every block must contain at least one address, but on some chains this is not true (for example, on some private chains).
You may turn this warning off by starting chifra scrape with the undocumented --allow_missing option. This will
disable the warning and allow the scraper to continue.
This error may also manifest itself with the message "A block was not processed."
Important note: On some chains, there are long stretches of such empty blocks. In this case, --allow_missing may
not fix the problem. --allow_missing works on one or a small number of missing blocks in a row, but extended ranges
of missing blocks may still cause a problem. This is related to how many blocks chifra scrape process in a single pass.
By default, the scraper processes 2,000 blocks at a time. If the range of empty blocks is larger than 2,000, even
settting --allow_missing will not help. In this case, you must increase the number of blocks processed in a pass
to be larger than the number of empty blocks in a row. Do this with the --block_cnt option. For example, --block_cnt 5000
-- Must I have a copy of the Unchained Index in order to use chifra?
Since TrueBlocks only provides Unchained Index data for Eth mainnet, Sepolia, and Gnosis, how can I run the chifra init for Polygon?
This is a very, very good question. TrueBlocks is not a "service." By that, I mean that we do not provide you (the user) with anything other than the ability to create and use the Unchained Index yourself. It's as if we were giving you a hammer as opposed to, say, being carpenter that you can hire to complete a project. We provide Eth mainnet, Sepolia, and Gnosis because we need those chains. If someone else needs a different chain, they need to provide it for themselves. The innovation that TrueBlocks makes is that (if it makes any), is to allow you to provide the index for yourself. Furthermore, with TrueBlocks, the index is shared with other people without doing anything special. Super importantly -- other people can share perhaps other data with you. And it flows out from there. TrueBlocks is purposefully designed this way because "decentralization," which we believe must work by default.
-- How do I build an index?
cryptoguru — Yesterday at 3:10 PM I did scan the docs, but nothing really stood out to me as the way to define a sort of schema to build an index Definitely open to any ideas you may have as input tjayrush — Yesterday at 5:18 PM So our software works by creating an index of what we call "appearances." An appearance is a <blockNumber.txid> pair list, for each address, where that address appears on the chain. Later, you can query that index to build a list of transactions and only then would you pull the actual transactional (or trace or log) data from the chain. You can choose to do anything you like with that data. By default, it generates either JSON, TXT, or CSV data. We don't impose any sort of database on the data.
This article describes exactly the example you mention -- pulling all UniSwap pairs: https://tjayrush.medium.com/recipe-factories-ce78fa4c5f5b
Another article discusses how to get monthly balances for a collection of accounts: https://tjayrush.medium.com/recipe-monthly-token-balances-ff6a302fda80 Medium Recipe: Factories Getting a list of all contracts created by an address Medium Recipe: Monthly Token Balances Or, Just How Bad was my year? cryptoguru — Yesterday at 11:29 PM This is an excellent explanation! Thanks for sharing the blog post recipes, seems to be a great practical example with a starting point of how to make use of it for my use case. I'll take a further look and try out the examples!
-- Is it normal for the index to be about six minutes behind the head?
A conversation with a user:
Hi everyone, newbie here. Is it normal for the finalized chunks on eth mainnet to be about 6 minutes behind the latest block? Or is there a setting I can configure to help keep the finalized chunks closer to the head? tjayrush — Today at 7:11 PM is it normal for the finalized chunks on eth mainnet to be about 6 minutes behind the latest block?
Yes. We purposefully stay 28 blocks behind the head because the head is "unsettled." 28 is a bit arbitrary, especially since The Merge where I think finalization is way sooner. is there a setting I can configure to help keep the finalized chunks closer to the head?
When you do chifra export, you can add --unripe to the command line. I'm not 100% sure how that works exactly. I think it will only show transactions less than 28 blocks old, but it may show all transactions. You can experiment. This feature is "under-tested" which means it works, but not sure how well, to be honest. Breezy — Today at 7:15 PM Thanks @tjayrush!
My most recent finalized block is 16527791 and at the time the last finalized block on etherscan is 16530233. So mine is 2442 block behind. You're saying it should only be 28 blocks behind? tjayrush — Today at 7:28 PM The wording is a bit confusing. Our "finalized" blocks are older than 28 blocks and exist in two possible states. "Finalized" and "staged." Both types will no longer be considered (that is, we won't query for these blocks any longer). "Finalized" blocks are stored in chunks and pinned to IPFS. "Staged" data is "final" in the sense that we won't query it again, but it's not yet put into a chunk.
When you do chifra export (without --unripe) you get both types, so you're always running against blocks 28 blocks or older (around 6 minutes).
--unripe shows blocks less than six minutes old.
Does that help?
The Magizine Model
Magazines have exactly the same qualities as immutable data. They publish periodically. They cannot go back and correct something previously published. They publish in chunks (issue) and collect those issues in volumes (manifests) and make corrections via errata. And can be indexed and sliced and diced.
We should study the library science of magizine publishing. How do librarians organize magazines? How do magizines organize themselves.
We should change our code to reflect this and suggest to the guy who's doing the EIPs that he use the magizine metaphor over the book metaphor. Books are multi-chapter, but they are not published periodically.
We can offer Uniswap a magizine publishing model (and it should not escape our notice that magizines have subscribers).
They can:
- provide dashboards showing all sorts of information from a raw data viewpoint -- transactions, blocks, traces, logs, neighbors, etc.
- they can publish volumes/issues/articles/pages of downloadable data via the Unchained Index
Have a question: can I start using
chifra servewhen I am in the middle ofchifra scrape
? dawid — Yesterday at 10:07 AM Yes you can, but you won’t get complete data tjayrush — Yesterday at 11:19 AM Slight addendum. You'll get complete data for all tools other than chifra export and chifra list because only these two are dependent on the index which is being created by chifra scrape. For those two tools, you'll get as data as far along as the scraper is in its scan.
Have a question related to chain-reorgs, when using chifra scrape - how if any reorg is handled ?
Another freaking excellent question. I have to write about this one at some point. (@Dodson, can you copy this response out somewhere and save it for later?)
We can't stay up to the very front of the chain because it changes all the time. I don't have solid numbers, but the chain reorgs many many times a day. For the reason, we consider three different types of data when scraping. We call the 'green', 'yellow', or 'red,' and just like a traffic light you can 'move forward', 'be cautious', or 'proceed at high risk' with the data. Ro Ma — Today at 5:43 PM I am considering to implement something related to this issue, for now I have an idea to use geth, since it has RPC notification related to reorg ( as far as I understand ). So another small store + index only for last hour of data, that knows how to handle reorgs. Interesting what about erigon & reorgs ... tjayrush — Today at 5:52 PM The 'green' results of the scrape are at least 28 blocks old (about six minutes). This is an arbitrary number, but about 1.5 times longer than an article we found where Vitalik says one should wait around four minutes for 'effective finality.' Of course, it's not perfect -- the chain can revert hundreds of blocks, but we have to stop looking at some point. One reason we thing this is okay is because we do a 'reconciliation'. Which means we use regular accounting procedures to 'double check the double checking.' It's kind of the best we can do.
The 'yellow' results get put in a folder we call 'ripe' which means that the scraper will 'reconsider' the blocks one more time before moving them to the 'staging' folder. A block in the 'staging' folder is 'green', but has not yet been 'consolidated' (i.e. put into a binary chunk and published to IPFS). 'Yellow' blocks are at least six blocks old (around 1.5 minutes), but less than 28 blocks.
'Red' blocks are stored in the 'unripe' folder and are less than six blocks old. You can expect them to change without notice.
Here's a ridiculously hurried graphic that I just threw together: Attachment file type: acrobat Red-Yellow-Green.pdf 29.90 KB tjayrush — Today at 6:01 PM If you run TEST_MODE=true chifra export --help you will see some additional hidden options -- in particular, --staging and --unripe (now that I'm writing this it appears there's a missing --ripe option.
If you add no additional option chifra export will export only from the consolidated data (i.e. green and consolidated -- the chunked data).
If you run chifra export --staging, it will output only data from the staging folder (i.e. green, but not yet consolidated).
If you run chifra export --unripe, it should output only red data, but I'm skeptical. (I think this may be a bug -- it may actually output yellow data.)
We don't have this option, but if you run chifra export --ripe it should export yellow data only.
There is no option currently to export everything. And I can see that we should have an option to export --pending, although that is not yet implemented either.
(Sorry for the long-windedness. I'm writing this in detail, so I can copy it into an issue.)
-- Are there commands to check the consistency of the Unchained Index?
Answer: chifra chunks index --check does some high level consistency checks (but this does require someone to have published the manifest hash to the smart contract, so maybe that doesn't work.
There's also chifra chunks index --check --deep which digs into the files themselves and checks that each address in the file reports true when the associated bloom filter is queried.
As far as answering the question, "Is this the exact result that one should get from building the index X?" I'm not sure that's even possible. The way "we" handled that issue is by allowing anyone to publish the hash of the manifest to the Unchained Index smart contract and then we compare the results. Another way is to by rebuilding it from scratch against different client software. We've done that twice since inception
You may also export "everything" in each chunk with chifra chunks addresses --verbose --fmt json but this is very, very verbose. It produces data per-chunk, so you must combine results for a single address, for example from many reports. Not optimal.
Build Problems
-- What are the requirements for building and running TrueBlocks?
XXX
-- I am having uild problems. Can you help?
When run the make command, I got this error:
/data/github/trueblocks-core/src/libs/utillib/sfos.cpp:21:10: fatal error: filesystem: No such file or directory
#include <filesystem>
compilation terminated.
libs/utillib/CMakeFiles/util.dir/build.make:902: recipe for target 'libs/utillib/CMakeFiles/util.dir/sfos.cpp.o' failed
Answer: Upgrade Ubuntu to latest version. See this https://stackoverflow.com/questions/39231363/fatal-error-filesystem-no-such-file-or-directory.
About the project
-- Why does TrueBlocks use a file-based cache?
Kevin11 — Yesterday at 10:08 PM Just curious why the TrueBlocks caches results as files?
i guess 99% of users don't have this issue but I ran out of inodes tjayrush — Today at 8:30 AM On a local machine, caching to a binary file is about as fast as one can get. I've always thought though that this cache could be in a database (either locally or remote). I just never got around to writing that. Mostly because the cache code is currently in C++. We're no longer writing C++ and part of our work for this year is to fully port everything to GoLang. Once we get the cache ported to GoLang, then we have a bunch of easier to implement options. May I ask the results of chifra list
--count shows for the address that blow out the disc space so much so that you ran out of inodes? (In other words, which address?) Also, are you caching transactions or traces? Also, are you using the --accounting options?-- What's the long term vision for TrueBlocks?
Answer:
- 30-year vision: you can't buy a computer of any type without a blockchain node inside and that blockchain node is so well indexed, anyone can get any portion of the entire history of the world without asking permission.
- 15-year vision: a special type of node software called an indexing node that does not carry the actual details of the chain, but can build the index and share it for free.
- 5-year vision: a large number of end-user (probably desktop) application built upon an excellent, complete, automatically-shared, super-fast index.
- 1-year vision: complete the work we promised to the Ethereum Foundation as described here: Ethereum Foundation Grant - TrueBlocks
- 1-month vision: get a speaking gig at EthDenver.
- 1-day vision: finish porting chifra traces to GoLang.
-- What is your policy on new features?
Answer:
- New features are "sort of" on hold for now as we port the entire C++ code base to GoLang. Once that's completed, we will focus on improving speed by taking advantage of GoLang's natural concurrency. Throughout our development, as new features are requested/suggested, if the feature can be added relatively easily to the GoLang code, we may add them. If the suggested feature needs to be added to the C++ code, it probably won't be added.
System Architecture
High-Level Architecture Diagram
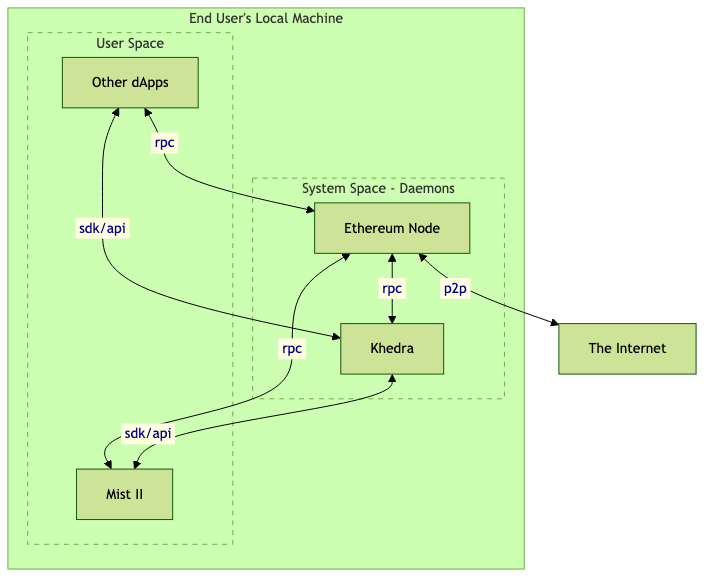
Chifra Command Line"
The chifra command provides access to all the applications and tools available:
Purpose:
Access to all TrueBlocks tools (chifra <cmd> --help for more).
Accounts:
list list every appearance of an address anywhere on the chain
export export full detail of transactions for one or more addresses
monitors add, remove, clean, and list address monitors
names query addresses or names of well known accounts
abis fetches the ABI for a smart contract
Chain Data:
blocks retrieve one or more blocks from the chain or local cache
transactions retrieve one or more transactions from the chain or local cache
receipts retrieve receipts for the given transaction(s)
logs retrieve logs for the given transaction(s)
traces retrieve traces for the given transaction(s)
when find block(s) based on date, blockNum, timestamp, or 'special'
Chain State:
state retrieve account balance(s) for one or more addresses at given block(s)
tokens retrieve token balance(s) for one or more addresses at given block(s)
Admin:
status report on the status of the TrueBlocks system
serve serve the TrueBlocks API using the flame server
scrape scan the chain and update (and optionally pin) the TrueBlocks index of appearances
chunks manage and investigate chunks and bloom filters
init initialize the TrueBlocks system by downloading from IPFS
Other:
quotes update or display Ethereum price data, this tool has been deprecated
explore open a local or remote explorer for one or more addresses, blocks, or transactions
slurp fetch data from EtherScan for any address
Flags:
-h, --help display this help screen
Use "chifra [command] --help" for more information about a command.
Click on the links to the left for more information on each command
Using chifra
Like git, TrueBlocks has a command called chifra that gives you access to all of the other subcommands.
Type:
chifra
You will see a long list of commands similar to this
Usage: chifra command
Purpose: Access to all TrueBlocks tools (chifra <cmd> --help for more).
Where:
Accounts:
list list every appearance of an address anywhere on the chain
export export full details of transactions for one or more addresses
monitors add, remove, clean, and list address monitors
names query addresses or names of well-known accounts
abis fetches the ABI for a smart contract
Chain Data:
blocks retrieve one or more blocks from the chain or local cache
transactions retrieve one or more transactions from the chain or local cache
receipts retrieve receipts for the given transaction(s)
logs retrieve logs for the given transaction(s)
traces retrieve traces for the given transaction(s)
when find block(s) based on date, blockNum, timestamp, or 'special'
Chain State:
state retrieve account balance(s) for one or more addresses at given block(s)
tokens retrieve token balance(s) for one or more addresses at given block(s)
Admin:
config report on and edit the configuration of the TrueBlocks system
daemon initialize and control long-running processes such as the API and the scrapers
scrape scan the chain and update the TrueBlocks index of appearances
chunks manage, investigate, and display the Unchained Index
init initialize the TrueBlocks system by downloading from IPFS
Other:
explore open a local or remote explorer for one or more addresses, blocks, or transactions
slurp fetch data from Etherscan for any address
You may get more help on any command by typing chifra <cmd> --help.
Getting status
Let's look at an easy command to get started called config.
chifra config
If you get a valid response, congratulations, your installation is working. You may skip ahead to the 'Using TrueBlocks' section below.
Troubleshooting
Depending on your setup, you may get the following error message when you run some chifra commands:
Warning: A request to your Ethereum node (http://localhost:8545) resulted
in the following error [Could not connect to server]. Specify a valid
rpcProvider by editing $CONFIG/trueblocks.toml.
If you get this error, edit the configuration file mentioned. The file is well documented, so refer to that file for further information.
When the chifra config command returns a valid response, you may move to the next section. If
you continue to have trouble, join our discord disscussion.
Using chifra
If you've gotten this far, you're ready to use TrueBlocks.
Let's try another simple command to show Ethereum block data. This command shows every 10th block between the first and the 100,000th.
chifra blocks 0-100000:10
Hit Control+C to stop the processing.
This shows one of the basic ideas behind TrueBlocks: make the Ethereum data easier to use.
Play around with other options. See what you can do.
Conclusion
By this point, you should have TrueBlocks properly installed and be able to get simple blockchain data from your node. All of the chifra commands should now work. The next section further introduces you to chifra.
Please see the Using Chifra page to proceed.
Tutorials
A few more examples in more detail.
Getting help
Every chifra sub-command comes with an associated help page. To get help for chifra itself, simply type
chifra
A long list of commands should show. (If you have trouble, see the Installation page.)
To get help for a specific command, type
chifra <cmd> --help
To get more detailed help, type
chifra <cmd> --help --verbose 2
Getting system status
The chifra command gives you access to all of TrueBlocks' functionality. Get system status by typing
chifra config
Getting blockchain data
Let's see if we can get some actual blockchain data.
Getting Blocks
The following command returns block data from block 2,001,002. The data is returned as JSON.
chifra blocks 2001002
Notice the full transactional details are included for each of the seven transactions in the block. You can show just the transaction hashes with
chifra blocks 2001002 --hashes
Copy one of those transaction hashes and paste it into the next command
chifra transactions 0x5f965c...9f26e12 # use the full hash
This command shows a single transaction's data. But, you may have noticed that the data is shown as tab separated rows. In general, block data (which is structured) is presented as JSON while primarily non-structured data is presented as TXT.
Formatting Output
Every chifra command accepts a few optional parameters including --verbose and --fmt. --verbose is useful when debugging. The --fmt option allows you to specify the format of the output. It accepts three values:
chifra blocks 2002 --fmt json # the default for blocks
chifra blocks 2002 --fmt txt # tab delimited text
chifra blocks 2002 --fmt csv # comma separated values
These options are available for all chifra commands. (Although in some cases, they are ignored.) One might wish to use the csv and txt options if one is engaged in data science for example.
More data commands
Below, we present a few of the other chifra commands without a lot of description.
Transactions and Logs and Traces, Oh My!
# The first transaction in block 2,002,002
chifra transactions 2001002.0
# All transactions in block 2,002,002 as comma separated values
chifra transactions --fmt csv 2001002.\*
# Every event in block 4,503,002
chifra logs --fmt json 4503002.\*
# Every event in block 4,503,002 -- articulated (see below)
chifra logs --fmt json --articulate 4503002.\*
# Every trace in the second transaction of block 4,503,002
chifra traces --fmt json --articulate 4503002.1
Please see the help files for chifra blocks --help and chifra transactions --help for more information, including all the options for specifying blocks and transactions (which are many and varied).
Articulated Data
Most TrueBlocks' commands accept an option called --articulate. The easiest way to explain articulated data is to say it is "ugly blockchain data turned into human readable text".
For example, the following command shows logs from the third transaction in block 4,503,002
chifra logs --fmt json 4503002.2
Pretty ugly. Compare that to this command
chifra logs --fmt json --articulate 4503002.2
You'll see additional (and much more easy to understand) data. In particular, you'll see an articulatedLog. That is "ugly log data presented in human-readable form."
See Getting ERC20 Transfer Events for an example of using articulation.
Links to more detail
There are many other chifra commands including list and export that we still study next. Other commands allow you to serve a JSON API presenting each command as an API route, init which pulls parts of the index data from IPFS, and scrape which builds the index.
In the following sections, each command is presented with its options and in more detail. In addition,
- Our blog has a few longer "tutorials"for accomplishing various tasks.
- Our data model reference describes the fields that are returned with each command
Accounts
The Accounts group of commands is at the heart of TrueBlocks. They allow you to produce and analyze transactional histories for one or more Ethereum addresses.
You may also name addresses; grab the ABI file for a given address; add, delete, and remove monitors, and, most importantly, export transactional histories in various formats, This includes re-directing output to remote or local databases.
To the right is a list of commands in this group. Click on a command to see its full documentation.
chifra list
chifra list takes one or more addresses, queries the index of appearances, and builds TrueBlocks
monitors. A TrueBlocks monitor is a file that contains blockNumber.transactionIndex pairs (transaction
identifiers) representing the history of the address.
Because TrueBlocks only extracts data from the Ethereum node when it's requested, the first time you list an address it takes about a minute. Subsequent queries are much faster because TrueBlocks caches the results.
Note that chifra list only queries the index, it does not extract the full transactional details.
You may use chifra export for that.
Purpose:
List every appearance of an address anywhere on the chain.
Usage:
chifra list [flags] <address> [address...]
Arguments:
addrs - one or more addresses (0x...) to list (required)
Flags:
-U, --count display only the count of records for each monitor
-z, --no_zero for the --count option only, suppress the display of zero appearance accounts
-b, --bounds report first and last block this address appears
-u, --unripe list transactions labeled unripe (i.e. less than 28 blocks old)
-s, --silent freshen the monitor only (no reporting)
-c, --first_record uint the first record to process
-e, --max_records uint the maximum number of records to process (default 250)
-E, --reversed produce results in reverse chronological order
-F, --first_block uint first block to export (inclusive, ignored when freshening)
-L, --last_block uint last block to export (inclusive, ignored when freshening)
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- No other options are permitted when --silent is selected.
Data models produced by this tool:
Links:
chifra export
The chifra export tools provides a major part of the functionality of the TrueBlocks system. Using
the index of appearances created with chifra scrape and the list of transaction identifiers
created with chifra list, chifra export completes the actual extraction of an address's transactional
history from the node.
You may use topics, fourbyte values at the start of a transaction's input data, and/or a log's
source address or emitter to filter the results.
You may also choose which portions of the Ethereum data structures (--transactions, --logs,
--traces, etc.) as you wish.
By default, the results of the extraction are delivered to your console, however, you may export the results to any database (with a little bit of work). The format of the data, its content and its destination are up to you.
Purpose:
Export full details of transactions for one or more addresses.
Usage:
chifra export [flags] <address> [address...] [topics...] [fourbytes...]
Arguments:
addrs - one or more addresses (0x...) to export (required)
topics - filter by one or more log topics (only for --logs option)
fourbytes - filter by one or more fourbytes (only for transactions and trace options)
Flags:
-p, --appearances export a list of appearances
-r, --receipts export receipts instead of transactional data
-l, --logs export logs instead of transactional data
-t, --traces export traces instead of transactional data
-n, --neighbors export the neighbors of the given address
-C, --accounting attach accounting records to the exported data (applies to transactions export only)
-A, --statements for the accounting options only, export only statements
-b, --balances traverse the transaction history and show each change in ETH balances
-i, --withdrawals export withdrawals for the given address
-a, --articulate articulate transactions, traces, logs, and outputs
-R, --cache_traces force the transaction's traces into the cache
-U, --count for --appearances mode only, display only the count of records
-c, --first_record uint the first record to process
-e, --max_records uint the maximum number of records to process (default 250)
-N, --relevant for log and accounting export only, export only logs relevant to one of the given export addresses
-m, --emitter strings for the --logs option only, filter logs to show only those logs emitted by the given address(es)
-B, --topic strings for the --logs option only, filter logs to show only those with this topic(s)
-V, --reverted export only transactions that were reverted
-P, --asset strings for the accounting options only, export statements only for this asset
-f, --flow string for the accounting options only, export statements with incoming, outgoing, or zero value
One of [ in | out | zero ]
-y, --factory for --traces only, report addresses created by (or self-destructed by) the given address(es)
-u, --unripe export transactions labeled unripe (i.e. less than 28 blocks old)
-E, --reversed produce results in reverse chronological order
-z, --no_zero for the --count option only, suppress the display of zero appearance accounts
-F, --first_block uint first block to process (inclusive)
-L, --last_block uint last block to process (inclusive)
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- Articulating the export means turn the EVM's byte data into human-readable text (if possible).
- For the --logs option, you may optionally specify one or more --emitter, one or more --topics, or both.
- The --logs option is significantly faster if you provide an --emitter or a --topic.
- Neighbors include every address that appears in any transaction in which the export address also appears.
- If present, --first_/--last_block are applied, followed by user-supplied filters such as asset or topic, followed by --first_/--max_record if present.
- The --first_record and --max_record options are zero-based (as are the block options).
- The _block and _record filters are ignored when used with the --count option.
- If the --reversed option is present, the appearance list is reversed prior to all processing (including filtering).
- The --decache option will remove all cache items (blocks, transactions, traces, etc.) for the given address(es).
- The --withdrawals option is only available on certain chains. It is ignored otherwise.
- The --traces option requires your RPC to provide trace data. See the README for more information.
Data models produced by this tool:
- appearance
- function
- log
- message
- monitor
- parameter
- receipt
- statement
- token
- trace
- traceaction
- traceresult
- transaction
- withdrawal
Links:
further info
The --traces option requires your node to enable the trace_block (and related) RPC endpoints. Please see the README file for the chifra traces command for more information.
chifra monitors
chifra monitors has two purposes: (1) to display information about the current set of monitors, and (2)
to --watch a set of addresses. The --watch function allows one to "follow" an address (or set
of addresses) and keep an off-chain database fresh.
Crud commands
chifra list creates a new monitor. See that tool's help file for more information.
The chifra monitors --delete command deletes (or --undelete if already deleted) an address but does not remove it from your hard drive. The monitor is marked as being deleted, making it invisible to other tools.
Use the --remove command to permanently remove a monitor from your computer. This is an
irreversible operation and requires the monitor to have been previously deleted.
The --decache option will remove not only the monitor but all of the cached data associated with
the monitor (for example, transactions or traces). This is an irreversible operation (except
for the fact that the cache can be easily re-created with chifra list <address>). The monitor need not have been previously deleted.
Watching addresses
The --watch command is special. It starts a long-running process that continually reads the blockchain looking for appearances of the addresses it is instructed to watch. It command requires two additional parameters: --watchlist <filename> and --commands <filename>. The --watchlist file is simply a list of addresses or ENS names, one per line:
0x5e349eca2dc61abcd9dd99ce94d04136151a09ee
trueblocks.eth
0x855b26bc8ebabcdbefe82ee5e9d40d20a1a4c11f
etc.
You may monitor as many addresses as you wish, however, if the commands you specify take longer than the --sleep amount you specify (14 seconds by default), the results are undefined. (Adjust --sleep if necessary.)
The --commands file may contain a list of any valid chifra command that operates on addresses. (Currently export, list, state, tokens.) Each command in the --commands file is executed once for each address in the --watchlist file. The --commands file may contain any number of commands, one per line with the above proviso. For example:
chifra list [{ADDRESS}]
chifra export --logs [{ADDRESS}]
etc.
The [{ADDRESS}] token is a stand-in for all addresses in the --watchlist. Addresses are processed in groups of batch_size (default 8).
Invalid commands or invalid addresses are ignored. If a command fails, the process continues with the next command. If a command fails for a particular address, the process continues with the next address. A warning is generated.
Purpose:
Add, remove, clean, and list address monitors.
Usage:
chifra monitors [flags] <address> [address...]
Arguments:
addrs - one or more addresses (0x...) to process
Flags:
--delete delete a monitor, but do not remove it
--undelete undelete a previously deleted monitor
--remove remove a previously deleted monitor
-C, --clean clean (i.e. remove duplicate appearances) from monitors, optionally clear stage
-l, --list list monitors in the cache (--verbose for more detail)
-c, --count show the number of active monitors (included deleted but not removed monitors)
-S, --staged for --clean, --list, and --count options only, include staged monitors
-w, --watch continually scan for new blocks and extract data as per the command file
-a, --watchlist string available with --watch option only, a file containing the addresses to watch
-d, --commands string available with --watch option only, the file containing the list of commands to apply to each watched address
-b, --batch_size uint available with --watch option only, the number of monitors to process in each batch (default 8)
-u, --run_count uint available with --watch option only, run the monitor this many times, then quit
-s, --sleep float available with --watch option only, the number of seconds to sleep between runs (default 14)
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- If no address is presented to the --clean command, all existing monitors will be cleaned.
- The --watch option requires two additional parameters to be specified: --watchlist and --commands.
- Addresses provided on the command line are ignored in --watch mode.
- Providing the value existing to the --watchlist monitors all existing monitor files (see --list).
Data models produced by this tool:
Links:
chifra names
chifra names is a surprisingly useful tool. It allows one to associate textual names with Ethereum
addresses. One may ask why this is necessary given that ENS exists. The answer is a single
word: "privacy". ENS names are public. In many cases, users desire to keep personal addresses
private. Try to do this on a website.
Like chifra abis, this tool is useful from the command line but is primarily used in support of
other tools, especially chifra export where naming addresses becomes the single best way to
turn unintelligible blockchain data into understandable information.
The various options allow you to search and filter the results. The tags option is used primarily
by the TrueBlocks explorer.
You may use the TrueBlocks explorer to manage (add, edit, delete) address-name associations.
Purpose:
Query addresses or names of well-known accounts.
Usage:
chifra names [flags] <term> [term...]
Arguments:
terms - a space separated list of one or more search terms (required)
Flags:
-e, --expand expand search to include all fields (search name, address, and symbol otherwise)
-m, --match_case do case-sensitive search
-a, --all include all (including custom) names in the search
-c, --custom include only custom named accounts in the search
-p, --prefund include prefund accounts in the search
-s, --addr display only addresses in the results (useful for scripting, assumes --no_header)
-g, --tags export the list of tags and subtags only
-C, --clean clean the data (addrs to lower case, sort by addr)
-r, --regular only available with --clean, cleans regular names database
-d, --dry_run only available with --clean or --autoname, outputs changes to stdout instead of updating databases
-A, --autoname string an address assumed to be a token, added automatically to names database if true
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The tool will accept up to three terms, each of which must match against any field in the database.
- The --match_case option enables case sensitive matching.
Data models produced by this tool:
Links:
chifra abis
The chifra abis tool retrieves one or more ABI files for the given address(es). It searches
for ABIs, sequentially, in the following locations:
- the current working folder,
- the TrueBlocks local cache,
- Etherscan,
- (in the future) ENS and Sourcify.
While this tool may be used from the command line, its primary purpose is in support of
the --articulate option for tools such as chifra export and chifra logs.
If possible, the tool will follow proxied addresses searching for the ABI, but that does not
always work. In that case, you may use the --proxy_for option.
The --known option prints a list of semi-standard function signatures such as the ERC20 standard,
ERC 721 standard, various functions from OpenZeppelin, various Uniswap functions, etc. As an
optimization, the known signatures are searched first during articulation.
The --encode option generates a 32-byte encoding for a given cannonical function or event signature. For
functions, you may manually extract the first four bytes of the hash.
The --find option is experimental. Please see the notes below for more information.
Purpose:
Fetches the ABI for a smart contract.
Usage:
chifra abis [flags] <address> [address...]
Arguments:
addrs - a list of one or more smart contracts whose ABIs to display (required)
Flags:
-k, --known load common 'known' ABIs from cache
-r, --proxy_for string redirects the query to this implementation
-l, --list a list of downloaded abi files
-c, --count show the number of abis downloaded
-f, --find strings search for function or event declarations given a four- or 32-byte code(s)
-n, --hint strings for the --find option only, provide hints to speed up the search
-e, --encode string generate the 32-byte encoding for a given cannonical function or event signature
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- Search for either four byte signatures or event signatures with the --find option.
Data models produced by this tool:
Links:
further information
Without the --verbose option, the result is a compacted form of the ABI. Add --verbose for full details.
The chifra abis --find option scans the cross product of two sets. The first set contains more than 100,000 function and event
names. The second set contains approximately 700 function signatures. The cross product of these two sets creates 70,000,000
combinations of name(signature) each of which is hashed to create either a four-byte or a 32-byte hash. Very infrequently,
the tool will find matches for an otherwise unknown signatures.
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Chain data
The Chain Data group of tools extract blockchain data directly from the node. You may extract block data, transactional data, receipts, logs, traces, and other information. Each tool has it own set of options, allowing you to get exactly the data you need.
To the right is a list of commands in this group. Click on a command to see its full documentation.
chifra blocks
The chifra blocks tool retrieves block data from your Ethereum node or, if previously cached, from the
TrueBlocks cache. You may specify multiple blocks per invocation.
By default, chifra blocks queries the full transactional details of the block (including receipts).
You may optionally retrieve only the transaction hashes in the block (which is significantly faster).
Additionally, you may also use this tool to retrieve uncle blocks at a give height.
Another useful feature of chifra blocks is the ability to extract address appearances from a block.
TrueBlocks uses a similar feature internally to build its index of appearances. This type of data
is very insightful when studying end user behavior and chain-wide adoption analysis.
Purpose:
Retrieve one or more blocks from the chain or local cache.
Usage:
chifra blocks [flags] <block> [block...]
Arguments:
blocks - a space-separated list of one or more block identifiers (required)
Flags:
-e, --hashes display only transaction hashes, default is to display full transaction detail
-c, --uncles display uncle blocks (if any) instead of the requested block
-t, --traces export the traces from the block as opposed to the block data
-u, --uniq display a list of uniq address appearances per transaction
-f, --flow string for the --uniq option only, export only from or to (including trace from or to)
One of [ from | to | reward ]
-l, --logs display only the logs found in the block(s)
-m, --emitter strings for the --logs option only, filter logs to show only those logs emitted by the given address(es)
-B, --topic strings for the --logs option only, filter logs to show only those with this topic(s)
-i, --withdrawals export the withdrawals from the block as opposed to the block data
-a, --articulate for the --logs option only, articulate the retrieved data if ABIs can be found
-U, --count display only the count of appearances for --addrs or --uniq
-X, --cache_txs force a write of the block's transactions to the cache (slow)
-R, --cache_traces force a write of the block's traces to the cache (slower)
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- Blocks is a space-separated list of values, a start-end range, a special, or any combination.
- Blocks may be specified as either numbers or hashes.
- Special blocks are detailed under chifra when --list.
- With the --logs option, optionally specify one or more --emitter, one or more --topics, either or both.
- The --logs option is significantly faster if you provide an --emitter and/or a --topic.
- Multiple topics match on topic0, topic1, and so on, not on different topic0's.
- The --decache option removes the block(s), all transactions in those block(s), and all traces in those transactions from the cache.
- The --withdrawals option is only available on certain chains. It is ignored otherwise.
- The --traces option requires your RPC to provide trace data. See the README for more information.
Data models produced by this tool:
Links:
further information
The --traces option requires your node to enable the trace_block (and related) RPC endpoints. Please see the README file for the chifra traces command for more information.
chifra transactions
The chifra transactions tool retrieves transactions directly from the Ethereum node or from the TrueBlocks cache (if present). You may specify multiple transaction identifiers
per invocation. Unlike the Ethereum RPC, the reported transactions include the transaction's receipt
and generated logs.
The --articulate option fetches the ABI from each encountered smart contract (including those
encountered in a trace--if the --trace option is enabled) to better describe the reported data.
The --trace option attaches an array transaction traces to the output (if the node you're querying
has --tracing enabled), while the --uniq option displays a list of uniq address appearances
instead of the underlying data (including uniq addresses in traces if enabled).
Purpose:
Retrieve one or more transactions from the chain or local cache.
Usage:
chifra transactions [flags] <tx_id> [tx_id...]
Arguments:
transactions - a space-separated list of one or more transaction identifiers (required)
Flags:
-a, --articulate articulate the retrieved data if ABIs can be found
-t, --traces include the transaction's traces in the results
-u, --uniq display a list of uniq addresses found in the transaction
-f, --flow string for the uniq option only, export only from or to (including trace from or to)
One of [ from | to ]
-l, --logs display only the logs found in the transaction(s)
-m, --emitter strings for the --logs option only, filter logs to show only those logs emitted by the given address(es)
-B, --topic strings for the --logs option only, filter logs to show only those with this topic(s)
-R, --cache_traces force the transaction's traces into the cache
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The transactions list may be one or more transaction hashes, blockNumber.transactionID pairs, or a blockHash.transactionID pairs.
- This tool checks for valid input syntax, but does not check that the transaction requested actually exists.
- If the queried node does not store historical state, the results for most older transactions are undefined.
- The --decache option removes the all transaction(s) and all traces in those transactions from the cache.
- The --traces option requires your RPC to provide trace data. See the README for more information.
Data models produced by this tool:
Links:
further information
The --traces option requires your node to enable the trace_block (and related) RPC endpoints. Please see the README file for the chifra traces command for more information.
chifra receipts
chifra receipts returns the given transaction's receipt. You may specify multiple transaction identifiers
per invocation.
The --articulate option fetches the ABI from each encountered smart contract (including those
encountered in a trace--if the --trace option is enabled) to better describe the reported data.
Generally speaking, this tool is less useful than others as you may report the same data using
chifra transactions and more focused data using chifra logs. It is included here for
completeness, as the receipt is a fundamental data structure in Ethereum.
Purpose:
Retrieve receipts for the given transaction(s).
Usage:
chifra receipts [flags] <tx_id> [tx_id...]
Arguments:
transactions - a space-separated list of one or more transaction identifiers (required)
Flags:
-a, --articulate articulate the retrieved data if ABIs can be found
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The transactions list may be one or more transaction hashes, blockNumber.transactionID pairs, or a blockHash.transactionID pairs.
- This tool checks for valid input syntax, but does not check that the transaction requested actually exists.
- If the queried node does not store historical state, the results for most older transactions are undefined.
Data models produced by this tool:
Links:
chifra logs
chifra logs returns the given transaction's logs. You may specify multiple transaction identifiers
per invocation.
The --articulate option fetches the ABI from each encountered smart contract to better describe
the reported data. The --topic and --source options allow you to filter your results.
Purpose:
Retrieve logs for the given transaction(s).
Usage:
chifra logs [flags] <tx_id> [tx_id...]
Arguments:
transactions - a space-separated list of one or more transaction identifiers (required)
Flags:
-m, --emitter strings filter logs to show only those logs emitted by the given address(es)
-B, --topic strings filter logs to show only those with this topic(s)
-a, --articulate articulate the retrieved data if ABIs can be found
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The transactions list may be one or more transaction hashes, blockNumber.transactionID pairs, or a blockHash.transactionID pairs.
- This tool checks for valid input syntax, but does not check that the transaction requested actually exists.
- If the queried node does not store historical state, the results for most older transactions are undefined.
- If you specify a 32-byte hash, it will be assumed to be a transaction hash, if it is not, the hash will be used as a topic.
Data models produced by this tool:
Links:
chifra traces
The chifra traces tool retrieves a transaction's traces. You may specify multiple transaction
identifiers per invocation.
The --articulate option fetches the ABI from each encountered smart contract to better describe
the reported data.
The --filter option calls your node's trace_filter routine (if available) using a bang-separated
string of the same values used by trace_fitler.
Purpose:
Retrieve traces for the given transaction(s).
Usage:
chifra traces [flags] <tx_id> [tx_id...]
Arguments:
transactions - a space-separated list of one or more transaction identifiers (required)
Flags:
-a, --articulate articulate the retrieved data if ABIs can be found
-f, --filter string call the node's trace_filter routine with bang-separated filter
-U, --count display only the number of traces for the transaction (fast)
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The transactions list may be one or more transaction hashes, blockNumber.transactionID pairs, or a blockHash.transactionID pairs.
- This tool checks for valid input syntax, but does not check that the transaction requested actually exists.
- If the queried node does not store historical state, the results for most older transactions are undefined.
- A bang separated filter has the following fields (at least one of which is required) and is separated with a bang (!): fromBlk, toBlk, fromAddr, toAddr, after, count.
- This command requires your RPC to provide trace data. See the README for more information.
Data models produced by this tool:
Links:
further information
The --traces option requires your node to enable the trace_block (and related) RPC endpoints. Many remote RPC providers do not enable these endpoints due to the additional load they can place on the node. If you are running your own node, you can enable these endpoints by adding trace to your node's startup.
The test for tracing assumes your node provides tracing starting at block 1. If your is partially synced, you may export the following enviroment variable before running the command to instruct chifra where to test.
export TB_<chain>_FIRSTTRACE=<bn>
where <chain> is the chain you are running and <bn> is the block number at which tracing starts. For example, to start tracing at block 1000 on the mainnet, you would export TB_MAINNET_FIRSTTRACE=1000.
chifra when
The chifra when tool answers one of two questions: (1) "At what date and time did a given block
occur?" or (2) "What block occurred at or before a given date and time?"
In the first case, supply a block number or hash and the date and time of that block are displayed. In the later case, supply a date (and optionally a time) and the block number that occurred at or just prior to that date is displayed.
The values for date and time are specified in JSON format. hour/minute/second are
optional, and if omitted, default to zero in each case. Block numbers may be specified as either
integers or hexadecimal number or block hashes. You may specify any number of dates and/or blocks
per invocation.
Purpose:
Find block(s) based on date, blockNum, timestamp, or 'special'.
Usage:
chifra when [flags] < block | date > [ block... | date... ]
Arguments:
blocks - one or more dates, block numbers, hashes, or special named blocks (see notes)
Flags:
-l, --list export a list of the 'special' blocks
-t, --timestamps display or process timestamps
-U, --count with --timestamps only, returns the number of timestamps in the cache
-r, --repair with --timestamps only, repairs block(s) in the block range by re-querying from the chain
-c, --check with --timestamps only, checks the validity of the timestamp data
-u, --update with --timestamps only, bring the timestamp database forward to the latest block
-d, --deep with --timestamps --check only, verifies timestamps from on chain (slow)
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The block list may contain any combination of number, hash, date, special named blocks.
- Block numbers, timestamps, or dates in the future are estimated with 13 second blocks.
- Dates must be formatted in JSON format: YYYY-MM-DD[THH[:MM[:SS]]].
Data models produced by this tool:
Links:
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Chain state
The two tools in this group deal with the Chain State. As chain state data concerns balances and byte code. it is distinct from Chain Data, which concerns things like blocks, transactions, or traces.
chifra state allows you to query the ETH account balance for an address, the byte code of a
smart contract (if available), the nonce, and other information about an address. The second tool,
chifra tokens, deals with ERC20 and ERC721 token balances and related data.
To the right is a list of commands in this group. Click on a command to see its full documentation.
Note: The amount of information you can retrieve depends on the type of node you run. Archive nodes and tracing allow you to query historical state (that is, all the way back to the genesis block). TrueBlocks works with non-archive nodes, but they are much less informative.
chifra state
The chifra state tool retrieves the balance of an address (or list of addresses) at the given block
(or blocks). Specify multiple addresses and/or multiple blocks if you wish, but you must specify
at least one address. If no block is specified, the latest block is reported.
You may also query to see if an address is a smart contract as well as retrieve a contract's byte code.
Purpose:
Retrieve account balance(s) for one or more addresses at given block(s).
Usage:
chifra state [flags] <address> [address...] [block...]
Arguments:
addrs - one or more addresses (0x...) from which to retrieve balances (required)
blocks - an optional list of one or more blocks at which to report balances, defaults to 'latest'
Flags:
-p, --parts strings control which state to export
One or more of [ balance | nonce | code | proxy | deployed | accttype | some | all ]
-c, --changes only report a balance when it changes from one block to the next
-z, --no_zero suppress the display of zero balance accounts
-l, --call write-only call (a query) to a smart contract
-d, --calldata string for commands (--call or --send), provides the call data (in various forms) for the command (may be empty for --send)
-a, --articulate for commands only, articulate the retrieved data if ABIs can be found
-r, --proxy_for string for commands only, redirects calls to this implementation
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- Blocks is a space-separated list of values, a start-end range, a special, or any combination.
- If the queried node does not store historical state, the results are undefined.
- Special blocks are detailed under chifra when --list.
- Balance is the default mode. To select a single mode use none first, followed by that mode.
- Valid parameters for --calldata include Solidity-like syntax: balanceOf(0x316b...), a four-byte followed by parameters: 0x70a08231(0x316b...), or encoded input data.
- You may specify multiple parts on a single line.
- In the --call string, you may separate multiple calls with a colon.
- Your use of the unaudited --send option legally absolves TrueBlocks, LLC or any associated parties from liability or loss related to such use.
- The --send option does not validate its input before sending your transaction to the network. If you provide invalid data, you may lose your funds. Be warned.
- As of version 4.0.0, use --call --calldata <cmd> to provide your command.
- --calldata may be one or more colon-seperated solidity calls, four-byte plus parameters, or encoded call data strings.
Data models produced by this tool:
Links:
chifra tokens
Given the address of an ERC20 token contract, the chifra tokens tool reports token balances for one or
more additional addresses. Alternatively, the tool can report the token balances for multiple ERC20
tokens for a single addresses.
In normal operation the first item in the address_list is assumed to be an ERC20 token
contract whose balances are being queried, whereas the remainder of the list is assumed to be
addresses on which to report.
In --byAcct mode, all addresses in the address_list are assumed to be ERC20 token contracts,
except the final one which is the account whose token balances are reported.
You may optionally specify one or more blocks at which to report. If no block is specified, the latest block is assumed. You may also optionally specify which parts of the token data to extract.
Purpose:
Retrieve token balance(s) for one or more addresses at given block(s).
Usage:
chifra tokens [flags] <address> <address> [address...] [block...]
Arguments:
addrs - two or more addresses (0x...), the first is an ERC20 token, balances for the rest are reported (required)
blocks - an optional list of one or more blocks at which to report balances, defaults to 'latest'
Flags:
-p, --parts strings which parts of the token information to retrieve
One or more of [ name | symbol | decimals | totalSupply | version | some | all ]
-b, --by_acct consider each address an ERC20 token except the last, whose balance is reported for each token
-c, --changes only report a balance when it changes from one block to the next
-z, --no_zero suppress the display of zero balance accounts
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- Blocks is a space-separated list of values, a start-end range, a special, or any combination.
- If the token contract(s) from which you request balances are not ERC20 compliant, the results are undefined.
- If the queried node does not store historical state, the results are undefined.
- Special blocks are detailed under chifra when --list.
- If the --parts option is not empty, all addresses are considered tokens and each token's attributes are presented.
Data models produced by this tool:
Links:
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Admin
The Admin group of commands allows you to query the status of the TrueBlocks system and manage various aspects including the Unchained Index. You may query the status; query for information about TrueBlocks caches; control the creation, sharing, and pinning of the Unchained Index; and even serve the data through an API.
See the API documentation for all information about using the API.
To the right is a list of commands in this group. Click on a command to see its full documentation.
chifra config
The chifra config program allows you to manage the various TrueBlocks caches. You may list all of the
caches, some of the cache, or even individual caches either in terse or full detail. The cache of
interest is specified with the modes option.
TrueBlocks maintains caches for the index of address appearances, named addresses, abi files, as well as other data including blockchain data, and address monitors.
Purpose:
Report on and edit the configuration of the TrueBlocks system.
Usage:
chifra config <mode> [flags]
Arguments:
mode - either show or edit the configuration
One of [ show | edit ]
Flags:
-a, --paths show the configuration paths for the system
-d, --dump dump the configuration to stdout
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Data models produced by this tool:
Links:
chifra status
The chifra status tool reports on the state (and size) of the various TrueBlocks local binary
caches. TrueBlocks produces nine difference caches: abis, blocks, monitors, names, objs,
recons, slurps, traces, transactions. In general practice, these caches may take up a
few GB of hard drive space, however, for very popular smart contract the size of the caches may
grow rather large. Keep an eye on it.
The chifra status program allows you to manage the various TrueBlocks caches. You may list all of the
caches, some of the cache, or even individual caches either in terse or full detail. The cache of
interest is specified with the modes option.
TrueBlocks maintains caches for the index of address appearances, named addresses, abi files, as well as other data including blockchain data, and address monitors.
Purpose:
Report on the state of the internal binary caches.
Usage:
chifra status <mode> [mode...] [flags]
Arguments:
modes - the (optional) name of the binary cache to report on, terse otherwise
One or more of [ index | blooms | blocks | transactions | traces | logs | statements | results | state | tokens | monitors | names | abis | slurps | staging | unripe | maps | some | all ]
Flags:
-d, --diagnose same as the default but with additional diagnostics
-c, --first_record uint the first record to process
-e, --max_records uint the maximum number of records to process (default 10000)
-a, --chains include a list of chain configurations in the output
-k, --healthcheck an alias for the diagnose endpoint
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The some mode includes index, monitors, names, slurps, and abis.
- If no mode is supplied, a terse report is generated.
Data models produced by this tool:
Links:
chifra daemon
chifra daemon manages chifra's API server. Each of the chifra commands along with all of its options,
are provided not only by the command line, but also the API server. We call this process the
flame server, which is written in Go. chifra serve is an alias for the chifra daemon command.
In the future, this daemon may also manage other long-running processes such as chifra scrape
and chifra monitors, but for now, it's only managing the API server.
If the default port for the API server is in use, you may change it with the --url option.
To get help for any command, please see the API documentation on our website. But, you may
also run chifra --help or chifra <cmd> --help on your command line to get help.
See below for an example of converting command line options to a call to the API. There's a one-to-one correspondence between the command line tools and options and the API routes and their options.
Purpose:
Initialize and control long-running processes such as the API and the scrapers.
Usage:
chifra daemon [flags]
Aliases:
daemon, serve
Flags:
-u, --url string specify the API server's url and optionally its port (default "localhost:8080")
--silent disable logging (for use in SDK for example)
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- To start API open terminal window and run chifra daemon.
- See the API documentation (https://trueblocks.io/api) for more information.
- The --port option is deprecated, use --url instead.
- The --grpc option is deprecated, there is no replacement.
- The --api option is deprecated, there is no replacement.
- The --scrape option is deprecated, use chifra scrape instead.
- The --monitor option is deprecated, use chifra monitors --watch instead.
Data models produced by this tool:
- none
Links:
- no api for this command
- source code
further information
To convert the options for a command line tool to an API call, do the following:
- Any
--snake_caseargument to the command line should be converted tocamelCase. For example,--no_headeron the command line should be sent as&noHeaderto the API server. - Any
switchon the command line, (i.e., options whose presence indicatestrueand whose absence indicatesfalse) should be sent as abooleanto the API server. For example,--no_headeron the command line should be sent as&noHeader=trueto the API server. If the option isfales, you do not need to send it to the API server. - Positionals such as the addresses, topics, and four-bytes for
chifra export, must be prepended with their positional name. For example,chifra export <address> <topic>should be sent as&addrs=<address>&topics=<topic>to the API server. For some commands (experiment) you may send more than one value for a positional with%20separating the entries or by sending multiple positionals (i.e.,&addrs=<address1>&addrs=<address2>).
Chifra was built for the command line, a fact we purposefully take advantage of to ensure continued operation on small machines. As such, this tool is not intended to serve multiple end users in a cloud-based server environment. This is by design. Be forewarned.
chifra scrape
The chifra scrape application creates TrueBlocks' chunked index of address appearances -- the
fundamental data structure of the entire system. It also, optionally, pins each chunk of the index
to IPFS.
chifra scrape is a long running process, therefore we advise you run it as a service or in terminal
multiplexer such as tmux. You may start and stop chifra scrape as needed, but doing so means the
scraper will not be keeping up with the front of the blockchain. The next time it starts, it will
have to catch up to the chain, a process that may take several hours depending on how long ago it
was last run. See the section below and the "Papers" section of our website for more information
on how the scraping process works and prerequisites for its proper operation.
You may adjust the speed of the index creation with the --sleep and --block_cnt options. On
some machines, or when running against some EVM node software, the scraper may overburden the
hardware. Slowing things down will ensure proper operation. Finally, you may optionally --pin
each new chunk to IPFS which naturally shards the database among all users. By default, pinning
is against a locally running IPFS node, but the --remote option allows pinning to an IPFS
pinning service such as Pinata.
Purpose:
Scan the chain and update the TrueBlocks index of appearances.
Usage:
chifra scrape [flags]
Flags:
-n, --block_cnt uint maximum number of blocks to process per pass (default 2000)
-s, --sleep float seconds to sleep between scraper passes (default 14)
-l, --touch uint first block to visit when scraping (snapped back to most recent snap_to_grid mark)
-u, --run_count uint run the scraper this many times, then quit
-d, --dry_run show the configuration that would be applied if run,no changes are made
-o, --notify enable the notify feature
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- The --touch option may only be used for blocks after the latest scraped block (if any). It will be snapped back to the latest snap_to block.
- This command requires your RPC to provide trace data. See the README for more information.
- The --notify option requires proper configuration. Additionally, IPFS must be running locally. See the README.md file.
Data models produced by this tool:
Links:
- no api for this command
- source code
configuration
Each of the following additional configurable command line options are available.
Configuration file: trueBlocks.toml
Configuration group: [scrape.<chain>]
| Item | Type | Default | Description / Default |
|---|---|---|---|
| appsPerChunk | uint64 | 2000000 | the number of appearances to build into a chunk before consolidating it |
| snapToGrid | blknum | 250000 | an override to apps_per_chunk to snap-to-grid at every modulo of this value, this allows easier corrections to the index |
| firstSnap | blknum | 2000000 | the first block at which snap_to_grid is enabled |
| unripeDist | blknum | 28 | the distance (in blocks) from the front of the chain under which (inclusive) a block is considered unripe |
| channelCount | uint64 | 20 | number of concurrent processing channels |
| allowMissing | bool | false | do not report errors for blockchains that contain blocks with zero addresses |
Note that for Ethereum mainnet, the default values for appsPerChunk and firstSnap are 2,000,000 and 2,300,000 respectively. See the specification for a justification of these values.
These items may be set in three ways, each overriding the preceding method:
-- in the above configuration file under the [scrape.<chain>] group,
-- in the environment by exporting the configuration item as upper case (with underbars removed) and prepended with (TB underbar SCRAPE underbar CHAIN) with the underbars included, or
-- on the command line using the configuration item with leading dashes and in snake case (i.e., --snake_case).
further information
Each time chifra scrape runs, it begins at the last block it completed processing (plus one). With
each pass, the scraper descends into each block's complete data. (This is why TrueBlocks requires
a --tracing node.) As the scraper encounters appearances of address in the
block's data, it adds those appearances to a growing index. Periodically (after processing the
block that contains the 2,000,000th appearance), the system consolidates an index chunk.
An index chunk is a portion of the index containing approximately 2,000,000 records (although, this number is adjustable for different chains). As part of the consolidation, the scraper creates a Bloom filter representing the set membership in the associated index portion. The Bloom filters are an order of magnitude smaller than the index chunks. The system then pushes both the index chunk and the Bloom filter to IPFS. In this way, TrueBlocks creates an immutable, uncapturable index of appearances that can be used not only by TrueBlocks, but any member of the community who needs it. (Hint: We all need it.)
Users of of any of the TrueBlocks applications (or anyone else's applications) may subsequently download the Bloom filters, query them to determine which index chunks need to be downloaded, and thereby build a historical list of transactions for a given address. This is accomplished while imposing a minimum amount of resource requirement on the end user's machine.
Recently, we enabled the ability for the end user to pin these downloaded index chunks and blooms on their own machines. The user needs the data for the software to operate--sharing requires minimal effort and makes the data available to other people. Everyone is better off. A naturally-occuring network effect.
tracing
The chifra scrape command requires your node to provide the trace_block (and related) RPC endpoints. Please see the
README file for the chifra traces command for more information.
prerequisites
chifra scrape works with any EVM-based blockchain, but does not currently work without a "tracing,
archive" RPC endpoint. The Erigon and Reth blockchain nodes, given their minimal disc footprint for an
archive node and their support of the required trace_ endpoint routines, are recommended.
Please see this article for more information about running the scraper and building and sharing the index of appearances.
notifications
The chifra scrape command provides a notification feature which is used primarily for trueblocks-key.
To configure it, you must edit the trueBlocks.toml file. You may edit the configuration file with
chifra config edit. Add the following configuration items to the [settings] group:
[settings.notify]
url = "http://localhost:5555" # or other
author = "TrueBlocks" #optional
In addition, you must enable the feature by adding the --notify option to the command line.
chifra chunks
The chifra chunks routine provides tools for interacting with, checking the validity of, cleaning up,
and analyzing the Unchained Index. It provides options to list pins, the Manifest, summary data
on the index, Bloom filters, addresses, and appearances. While still in its early stages, this
tool will eventually allow users to clean their local index, clean their remote index, study
the indexes, etc. Stay tuned.
Purpose:
Manage, investigate, and display the Unchained Index.
Usage:
chifra chunks <mode> [flags] [blocks...] [address...]
Arguments:
mode - the type of data to process (required)
One of [ manifest | index | blooms | pins | addresses | appearances | stats ]
blocks - an optional list of blocks to intersect with chunk ranges
Flags:
-c, --check check the manifest, index, or blooms for internal consistency
-i, --pin pin the manifest or each index chunk and bloom
-p, --publish publish the manifest to the Unchained Index smart contract
-r, --remote prior to processing, retrieve the manifest from the Unchained Index smart contract
-b, --belongs strings in index mode only, checks the address(es) for inclusion in the given index chunk
-F, --first_block uint first block to process (inclusive)
-L, --last_block uint last block to process (inclusive)
-m, --max_addrs uint the max number of addresses to process in a given chunk
-d, --deep if true, dig more deeply during checking (manifest only)
-e, --rewrite for the --pin --deep mode only, writes the manifest back to the index folder (see notes)
-U, --count for certain modes only, display the count of records
-s, --sleep float for --remote pinning only, seconds to sleep between API calls
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- Mode determines which type of data to display or process.
- Certain options are only available in certain modes.
- If blocks are provided, only chunks intersecting with those blocks are displayed.
- The --truncate option updates the manifest and removes local data, but does not alter remote pins.
- The --belongs option is only available in the index mode.
- The --first_block and --last_block options apply only to addresses, appearances, and index --belongs mode.
- The --pin option requires a locally running IPFS node or a pinning service API key.
- The --publish option requires a private key.
- The --publisher option is ignored with the --publish option since the sender of the transaction is recorded as the publisher.
- Without --rewrite, the manifest is written to the temporary cache. With it, the manifest is rewritten to the index folder.
Data models produced by this tool:
- appearance
- appearancetable
- chunkaddress
- chunkbloom
- chunkindex
- chunkpin
- chunkrecord
- chunkstats
- count
- ipfspin
- manifest
- message
- rangedates
- reportcheck
Links:
chifra init
When invoked, chifra init reads a value from a smart contract called The Unchained Index
(0x0c316b7042b419d07d343f2f4f5bd54ff731183d).
This value (manifestHashMap) is an IPFS hash pointing to a pinned file (called the Manifest) that
contains a large collection of other IPFS hashes. These other hashes point to each of the Bloom
filter and Index Chunk. TrueBlocks periodically publishes the Manifest's hash to the smart contract.
This makes the index available for our software to use and impossible for us to withhold. Both of
these aspects of the manifest are by design.
If you stop chifra init before it finishes, it will pick up again where it left off the next
time you run it.
Certain parts of the system (chifra list and chifra export for example) if you have not
previously run chifra init or chifra scrape. You will be warned by the system until it's
satisfied.
If you run chifra init and allow it to complete, the next time you run chifra scrape, it will
start where init finished. This means that only the blooms will be stored on your hard drive.
Subsequent scraping will produce both chunks and blooms, although you can, if you wish delete
chunks that are not being used. You may periodically run chifra init if you prefer not to scrape.
Purpose:
Initialize the TrueBlocks system by downloading the Unchained Index from IPFS.
Usage:
chifra init [flags]
Flags:
-a, --all in addition to Bloom filters, download full index chunks (recommended)
-e, --example string create an example for the SDK with the given name
-d, --dry_run display the results of the download without actually downloading
-F, --first_block uint do not download any chunks earlier than this block
-s, --sleep float seconds to sleep between downloads
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- If run with no options, this tool will download or freshen only the Bloom filters.
- The --first_block option will fall back to the start of the containing chunk.
- You may re-run the tool as often as you wish. It will repair or freshen the index.
Data models produced by this tool:
Links:
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Other
The commands in the Other group provide useful miscellaneous features.
chifra exploreprovides a quick way to open the configured blockchain explorer,ethslurp(an older tool) allows you call extract data from Etherscan.
To the right is a list of commands in this group. Click on a command to see its full documentation.
Note: Some of these tools, such as ethslurp, require an API key. Follow these instructions to add a key to your config.
chifra explore
chifra explore opens Etherscan (and other explorers -- including our own) to the block identifier,
transaction identifier, or address you specify. It's a handy (configurable) way to open an explorer
from the command line, nothing more.
Purpose:
Open a local or remote explorer for one or more addresses, blocks, or transactions.
Usage:
chifra explore [flags] [terms...]
Arguments:
terms - one or more address, name, block, or transaction identifier
Flags:
-n, --no_open return the URL without opening it
-l, --local open the local TrueBlocks explorer
-g, --google search google excluding popular blockchain explorers
-h, --help display this help screen
Data models produced by this tool:
Links:
- no api for this command
- source code
chifra slurp
chifra slurp is the first tool we built in the Ethereum space. It even has its own website.
While it's useful, it has two shortcomings. First, it is fully centralized, pulling its data from http://etherscan.io. Second, is that it does not report every transaction for a given account. This is actually a shortcoming with API providers. It's too complicated to explain here, but see our blog.
While chifra slurp has its shortcomings, it does provides some nice features. You may use it to pull
any transaction initiated by an EOA for example or to explore mining rewards. Visit the above
referenced website for more information.
Currently supported API providers:
- TrueBlocks Key
- Etherscan
- Covalent
- Alchemy
Purpose:
Fetch data from Etherscan and other APIs for any address.
Usage:
chifra slurp [flags] <address> [address...] [block...]
Arguments:
addrs - one or more addresses to slurp from Etherscan (required)
blocks - an optional range of blocks to slurp
Flags:
-r, --parts strings which types of transactions to request
One or more of [ ext | int | token | nfts | 1155 | miner | uncles | withdrawals | some | all ]
-p, --appearances show only the blocknumber.tx_id appearances of the exported transactions
-a, --articulate articulate the retrieved data if ABIs can be found
-S, --source string the source of the slurped data
One of [ etherscan | key | covalent | alchemy ] (default "etherscan")
-U, --count for --appearances mode only, display only the count of records
-g, --page uint the page to retrieve (page number)
--page_id string the page to retrieve (page ID)
-P, --per_page uint the number of records to request on each page (default 1000)
-s, --sleep float seconds to sleep between requests (default 0.25)
-H, --ether specify value in ether
-o, --cache force the results of the query into the cache
-D, --decache removes related items from the cache
-x, --fmt string export format, one of [none|json*|txt|csv]
-v, --verbose enable verbose output
-h, --help display this help screen
Notes:
- An address must be either an ENS name or start with '0x' and be forty-two characters long.
- Portions of this software are Powered by Etherscan.io, Covalent, Alchemy, TrueBlocks Key APIs.
- See slurp/README on how to configure keys for API providers.
- The withdrawals option is only available on certain chains. It is ignored otherwise.
- If the value of --source is key, --parts is ignored.
- The --types option is deprecated, use --parts instead.
Data models produced by this tool:
Links:
Adding provider API key
Call chifra config edit to edit the configuration file.
For TrueBlocks Key, add keyEndpoint = "your-key-endpoint-url" to chains.mainnet section.
For all other providers add an entry to keys section like this:
[keys]
[keys.etherscan]
apiKey = "etherscan-apikey"
[keys.covalent]
apiKey = "covalent-apikey"
[keys.alchemy]
apiKey = "alchemy-apikey"
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Globals
Global Options
Every chifra command has the following globally available options (unless the option is removed as shown in the Disabled column below). Certain commands have additional globally available features as noted in the Enabled column.
| Globally Options Available to All Commands |
|---|
| Verbose, Fmt, Version, Chain, NoHeader, File, Output, Append, Help |
Where:
-v, --verbose enable verbose output -x, --fmt string export format, one of [none|json*|txt|csv] --version displays the current version string --chain instructs the tool to operate against the given chain --no_header suppresses the display of the header in txt and csv format --file reads options from the specified file --output redirects output to the given file --append for --output only, appends results to the given file -h, --help displays the help screen
Group 1
The tools in this group of commands produce data but do not need the cache because they do not query the node. They all have the above globally available options.
| Group | Cmd | Enabled | Disabled |
|---|---|---|---|
| accounts | list | ||
| accounts | monitors | ||
| accounts | names | ||
| admin | config | ||
| admin | status | ||
| admin | chunks |
Group 2
The tools in this group have all of the above options, but they query the node, therefore they need the cache.
| Group | Cmd | Enabled | Disabled |
|---|---|---|---|
| accounts | abis | Cache, Decache | |
| chain_data | when | Cache, Decache | |
| chain_state | tokens | Cache, Decache |
Where:
-o, --cache force the results of the query into the cache -D, --decache removes related items from the cache
Group 3
The tools in this group have all of the above options, but because they do query the node, they need the cache. They also produce wei values therefore they have the --ether option as well.
| Group | Cmd | Enabled | Disabled |
|---|---|---|---|
| accounts | export | Cache, Decache, Ether | |
| chain_state | state | Cache, Decache, Ether |
Where:
-H, --ether specify value in ether
Group 4
As of version 2.6.0, the --raw option has been removed in its entirity.
Prior to that version, the following tools had this option which would pass
the data received directly from the node without modification.
chifra blocks
chifra transactions
chifra receipts
chifra logs
chifra traces
chifra slurp
Group 5
This final group of tools do not produce any real data. They are mostly used for configuration and/or to start and stop long-running processes. They allow no additional options over the default, but disable the following options depending on context. The deamon option, which provides all the tools via a local API, disables --chain because one sends chain with the URL.
| Group | Cmd | Enabled | Disabled |
|---|---|---|---|
| admin | daemon | Output, Append, Fmt, NoHeader, File, Chain | |
| admin | scrape | Output, Append, Fmt, NoHeader, File | |
| admin | init | Output, Append, Fmt, NoHeader, File | |
| other | explore | Output, Append, Fmt, NoHeader |
Configurations
Many of the chifra commands allow you to customize their behaviour through configuration files
and/or environment variables. These options are documented here.
Environment variables
Each command-line option may be overridden by exporting an environment variable in your shell prior
to running a chifra command.
The name of those environment variables is as follows:
- The environment variable beings with
TB_ - The environment variable is
ALL_UPPER_CASE - The environment variable name removes underbars from the
item_name(item_namebecomesITEMNAME) - The environment variable name starts with the
groupthe item belongs to
For example: TB_GROUP_ITEMNAME.
A more concrete example might be:
export TB_SETTINGS_RPCPROVIDER=http://localhost:9876
chifra blocks 100
which would cause chifra to use an alternate rpcProvider without having to edit the
configuration file.
This feature comes in handy when build shell scripts to automate various tasks with chifra.
Where are configs stored?
The configuration files for chifra are stored in the operating system specific locations in the
TrueBlocks folder.
Separate files
A single global configuration, called trueBlocks.toml, which stores all the configuration items, is located at the root of the configuration folder.
The remained of this documentation is incorrect. See the configuration file itself or the source code for more information.
Note: As of version 2.5.2, this is no longer true.
In addition, each individual tool may have its own configuration file with items peculuar to that tool. If a configuration item is found in a particular file, it applies only to that tool.
If, however, one of the items documented below under trueBlocks.toml is found in a tool's
individual config, it will override that value for that tool only.
For historical reasons, the configuration files are names based on old tool names. Please see the table below for the name of each tool's config file.
Multichain
If you're running against mutliple chains, you may place any of these files in the root of the chain's configuration folder, and the values found there will replace any values found at the top level. In this way, you may configure all chains for certain values, but customize your configuration per chain.
Configuration files
| Item | Description / Default |
|---|---|
| [settings] | |
| rpcProvider | The RPC endpoint (required) http://localhost:8545 |
| cachePath | Location of binary cache $CONFIG/cache/ |
| indexPath | Location of unchained index $CONFIG/unchained/ |
| etherscan_key | API key for Etherscan (optional) empty |
| [dev] | |
| debug_curl | Increases log level for curl commands false |
| Item | Description / Default |
|---|---|
| [display] | |
| format | Customizes default output of tool empty |
| Item | Description / Default |
|---|---|
| [settings] | |
| cache | If true, queried transactions are cached false |
| cache_traces | If true, queried traces are cached false |
| ether_rounding | When doing reconciliations, round to this number of decimals places 18 |
| start_when_deployed | For smart contracts only, if true, start scan when contract is first deployed. If false, scan entire history (slower)true |
| max_traces | For any given transaction, limit number of traces to this number 250 |
| skip_ddos | Skip over 2016 dDos attacks true |
| [display] | |
| format | Display format when exporting transactions (search source code) STR_DISPLAY_TRANSACTION |
| receipt | Display format when exporting receipts STR_DISPLAY_RECEIPT |
| log | Display format when exporting logs STR_DISPLAY_LOG |
| trace | Display format when exporting traces STR_DISPLAY_TRACE |
| appearances | Display format when exporting appearances STR_DISPLAY_APPEARANCE |
| neighbor | Display format when exporting neighbors STR_DISPLAY_APPEARANCE |
| statement | Display format when exporting statements STR_DISPLAY_RECONCILIATION |
| [exclusions] | |
| enabled | If true, exclude addresses in list from extractionsfalse |
| list | If [exclusions]enabled is true, exclude this list of addresses from extractionsempty |
Configuration group: [settings]
| Item | Type | Default | Description / Default |
|---|---|---|---|
| [settings] | |||
| apps_per_chunk | uint64 | 200000 | the number of appearances to build into a chunk before consolidating it |
| snap_to_grid | blknum | 100000 | an override to apps_per_chunk to snap-to-grid at every modulo of this value, this allows easier corrections to the index |
| first_snap | blknum | 0 | the first block at which snap_to_grid is enabled |
| unripe_dist | blknum | 28 | the distance (in blocks) from the front of the chain under which (inclusive) a block is considered unripe |
| channel_count | uint64 | 20 | number of concurrent processing channels |
| allow_missing | bool | false | do not report errors for blockchains that contain blocks with zero addresses |
| Item | Description / Default |
|---|---|
| [enabled] | |
| download_manifest | If true, download the index manifest prior to processing true |
| Item | Description / Default |
|---|---|
| [settings] | |
| skip_ddos | If true, skip over September 2016 dDos transactions true |
| max | If skip_ddos is true, this number of traces defines a 'dDos' transaction250 |
See the source code for information on customizing this tool -- this legacy code does not comply with other tools.
Other tools
The following tools are documented, but customizing them is not supported. If you change something here, and you break your installation, please don't tell us we didn't warn you.
| Item | Description / Default |
|---|---|
| [settings] | |
| api_provider | The location of the API endpoint gotten from chifra daemonhttp://localhost:8080 |
| run_local | If true, run tests labeled as local (most will fail)false |
| json_pretty_print | Post processor for API test cases (formats output to verify valid JSON production) jq . |
| test_epoch | The epoch to report in the performance testing tool - usually tracks current version E-<VERSION_MINOR> |
| copy_path | An alternate path to which to copy performance results |
| Item | Description / Default |
|---|---|
| [settings] | |
| disabled | If true, makeClass is enabled. Be warned -- this will overwrite source code file if improperly configured false |
| last_format | The timestamp at date the makeClass formatter was run 0 |
| [enabled] | |
| auto_format | If true, run the auto-formatter false |
| generate | If true, run the auto-code generator false |
| readmes | If true, generate README files with make generatefalse |
The follow values are defined for each classDefinition file
| Item | Description / Default |
|---|---|
| [settings] | |
| class | The name of the C++ class |
| fields | The name of the file holding the field definitions for the class |
| includes | The include files for the class's header file |
| cpp_includes | The include files for the class's c++ file |
| sort | If true, add sorting function to the class |
| equals | If true, add equality function to the class |
| contained_by | If present, the name of the class that contains items of this type |
| doc_producer | The name of the chifra tool that produces this type of data |
| doc_group | The documentation group this class belongs to |
| doc_descr | The description of the class for the documentation |
| doc_route | The command line tool and/or the API route |
| force_objget | Some flag for some reason false |
Data model
Reference pages about working with Ethereum and TrueBlocks-collected data. Jump to the data model introduction
Blockchain data

TrueBlocks data
On its own blockchain data is an unintelligable blob of binary bytes. But, we all know there is an amazing collection of deeply interesting information contained therein. Thousands of people are trading, voting, expressing their preferences, making markets for valueless items every minute.
What interests us about this data are answers to questions such as:
- What exactly is going on?
- Where is my money?
- Didn't I have some of those tokens somewhere?
- May I please just get a list of my transactions?
TrueBlocks allows you to query this type of information and more. Using the
chifra list option, one may list every detail of any transaction that happened
against one's own wallet address (or anyone else's for that matter).
The --articulate option, which is available on many commands, reanimates
or articulates the impossible-to-understand input and event data fields.
TrueBlocks even articulates trace data which reveals the deep history of
any transaction include multi-layer deep smart contract calls.
TrueBlocks works as easily with multiple related addresses at a time as it does with individual addresses. One can view entire asset balance histories, detailed voting histories for a DAO, or the ownership status on one's POAPs and ENS names. We even allow exporting of Open Financial Exchange files which is what your bank uses to export your transactions to accounting software.
Consistent apis / interfaces
Each of the TrueBlocks endpoints and command-line tools are built on
the same core libraries (many of which are in Go). Our server (chifra serve)
uses the command line tools directly to complete many of its tasks, therefore
the interfaces are identical. Applications built on top of TrueBlocks have
a consistent, stable data interface.
Open source
Furthermore, TrueBlocks is fully open source. If you don't like something, change it and make a PR (non-commercial use only). If you're a commercial entity, feel free to make changes, but remember, you must either license the code separately or release your modifications under the same open source license. Please contact us about our licensing plans if you have a non-public, commercial use case.
Unchained index

Benefits of unchaining the index
We've written a lot about the Unchained Index elsewhere. We won't belabour the point, however, we want to point out that the Unchained Index:
- Allows blazingly fast access to any account anywhere on the chain
- Allows perfectly-private access to query blockchain data completely locally
- Naturally shards itself and distributes itself using IPFS and user behaviour
- Is published periodically to a smart contract and once published cannot be removed from public use
- Is reproducable directly from immutable data with a well-defined series of operations meaning its as immutable as the original blockchain data
- Compact
- Digs deeper into the blockchain than any other source allowing for instantaneous, 18-decimal-place accurate off-chain reconciliation of any account
- Blazingly fast
Links to articles about TrueBlocks
Here we present a number of articles we've written about TrueBlocks over the years. Read at least a few of these and you will better understand what we're trying to do.
| Title and description |
|---|
| A Specification of the Unchained Index - in which we fully and in a detailed way explain the Unchained Index |
| A Long-Winded Explanation of TrueBlocks - in which we go on and on about how things work and why |
| How Accurate is EtherScan - in which we compare TrueBlocks with EtherScan's apis |
| Comparison of TrueBlocks and The Graph - in which we compare TrueBlocks to The Graph |
| Custom Traversers - in which we describe how to enhance the extracted data |
| Simple Undeniable Facts - in which we argue strongly for full decentralization |
| A Time-Ordered Log of an Index of a Time-Ordered Log - in which we describe why old-fashioned web 2.0 indexes don't cut it |
| Indexing Addresses on the Ethereum Blockchain - in which we describe the process of building the unchained index |
| Mother May I - in which we play a childish and churlish game with our users |
| Building an Account Scraper with TrueBlocks - in which we describe the technical details of building the index |
| How Many ERC20 Tokens Do I Have? - in which we describe why it's hard to know and how TrueBlocks helps |
| Accounting for the Revolution - a very early paper in which we first try to describe TrueBlocks |
Accounts
The primary tool of TrueBlocks is chifra export. This tool extracts, directly from the chain,
entire transactional histories for one or more addresses and presents that information for use
outside the blockchain. The results of this extraction is stored in a data structure called a
Monitor.
Monitors collect together Appearances (blknum.tx_id pairs)
along with additional information such as Reconciliations
(18-decimal place accurate accounting for each asset transfer), Names
(associations of human-readable names with addresses), and Abis
which track the "meaning" of each transaction through its Functions
and Parameters.
Each data structure is created by one or more tools which are detailed below.
Appearance
An appearance is a pointer (blknum, tx_id pair) into the blockchain indicating where a
particular address appears. This includes obvious locations such as to or from as well
as esoteric locations such as deep inside a tenth-level trace or as the miner of an uncle block.
The primary goal of TrueBlocks is to identify every appearance for any address on the chain.
The TrueBlocks index of appearances (created by chifra scrape) makes the production of such a list possible. Appearances are stored in Monitors.
The following commands produce and manage Appearances:
Appearances consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the address of the appearance | address |
| blockNumber | the number of the block | uint32 |
| transactionIndex | the index of the transaction in the block | uint32 |
| traceIndex | the zero-based index of the trace in the transaction | uint32 |
| reason | the location in the data where the appearance was found | string |
| timestamp | the timestamp for this appearance | timestamp |
| date | the timestamp as a date (calculated) | datetime |
Monitor
A Monitor is a list of Appearances associated with a given address along with various details about those appearances. A monitor is created when a user expresses interest in an address by calling either chifra list or chifra export tool (or querying thier associated APIs).
Once created, a monitor may be periodically freshened by calling either chifra list or chifra export, however, it is also possible to freshen a monitor continually with
chifra scrape --monitors. This tool watches the front of the
chain and repeatedly calls chifra list.
The following commands produce and manage Monitors:
Monitors consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the address of this monitor | address |
| name | the name of this monitor (if any) | string |
| nRecords | the number of appearances for this monitor | int64 |
| fileSize | the size of this monitor on disc | int64 |
| lastScanned | the last scanned block number | uint32 |
| isEmpty | true if the monitor has no appearances, false otherwise | bool |
| isStaged | true if the monitor file in on the stage, false otherwise | bool |
| deleted | true if this monitor has been deleted, false otherwise | bool |
Name
TrueBlocks allows you to associate a human-readable name with an address. This feature goes a long way towards making the blockchain data one extracts with a Monitor much more readable.
Unlike the blockchain data itself, which is globally available and impossible to censor, the association of names with addresses is not on chain (excepting ENS, which, while fine, is incomplete). TrueBlocks allows you to name addresses of interest to you and either share those names (through an on-chain mechanism) or keep them private if you so desire.
Over the years, we've paid careful attention to the 'airwaves' and have collected together a 'starter-set' of named addresses which is available through the chifra names command line. For example, every time people say "Show me your address, and we will airdrop some tokens" on Twitter, we copy and paste all those addresses. We figure if you're going to DOX yourselves, we might as well take advantage of it. Sorry...not sorry.
The following commands produce and manage Names:
Names consist of the following fields:
| Field | Description | Type |
|---|---|---|
| tags | colon separated list of tags | string |
| address | the address associated with this name | address |
| name | the name associated with this address (retrieved from on-chain data if available) | string |
| symbol | the symbol for this address (retrieved from on-chain data if available) | string |
| source | user supplied source of where this name was found (or on-chain if name is on-chain) | string |
| decimals | number of decimals retrieved from an ERC20 smart contract, defaults to 18 | uint64 |
| deleted | true if deleted, false otherwise | bool |
| isCustom | true if the address is a custom address, false otherwise | bool |
| isPrefund | true if the address was one of the prefund addresses, false otherwise | bool |
| isContract | true if the address is a smart contract, false otherwise | bool |
| isErc20 | true if the address is an ERC20, false otherwise | bool |
| isErc721 | true if the address is an ERC720, false otherwise | bool |
Bounds
The Bounds data model displays information about a given address including how many times it's appeared on the chain and when the first and most recent blocks, timestamps, and dates are.
The following commands produce and manage Bounds:
Bounds consist of the following fields:
| Field | Description | Type |
|---|---|---|
| count | the number of appearances for this address | uint64 |
| firstApp | the block number and transaction id of the first appearance of this address | Appearance |
| firstTs | the timestamp of the first appearance of this address | timestamp |
| firstDate | the first appearance timestamp as a date (calculated) | datetime |
| latestApp | the block number and transaction id of the latest appearance of this address | Appearance |
| latestTs | the timestamp of the latest appearance of this address | timestamp |
| latestDate | the latest appearance timestamp as a date (calculated) | datetime |
Statement
When exported with the --accounting option from chifra export, each transaction will have field
called statements. Statements are an array for reconciliations. All such exported transactions
will have at least one reconciliation (for ETH), however, many will have additional reconciliations
for other assets (such as ERC20 and ERC721 tokens).
Because DeFi is essentially swaps and trades around ERC20s, and because and 'programmable money' allows for unlimited actions to happen under a single transaction, many times a transaction has four or five reconciliations.
Reconciliations are relative to an accountedFor address. For this reason, the same transaction
will probably have different reconciliations depending on the accountedFor address. Consider a
simple transfer of ETH from one address to another. Obviously, the sender's and the recipient's
reconciliations will differ (in opposite proportion to each other). The accountedFor address
is always present as the assetAddress in the first reconciliation of the statements array.
The following commands produce and manage Statements:
Statements consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the number of the block | blknum |
| transactionIndex | the zero-indexed position of the transaction in the block | txnum |
| logIndex | the zero-indexed position the log in the block, if applicable | lognum |
| transactionHash | the hash of the transaction that triggered this reconciliation | hash |
| timestamp | the Unix timestamp of the object | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| assetAddr | 0xeeee...eeee for ETH reconciliations, the token address otherwise | address |
| assetSymbol | either ETH, WEI, or the symbol of the asset being reconciled as extracted from the chain | string |
| decimals | the value of decimals from an ERC20 contract or, if ETH or WEI, then 18 | value |
| spotPrice | the on-chain price in USD (or if a token in ETH, or zero) at the time of the transaction | float |
| priceSource | the on-chain source from which the spot price was taken | string |
| accountedFor | the address being accounted for in this reconciliation | address |
| sender | the initiator of the transfer (the sender) | address |
| recipient | the receiver of the transfer (the recipient) | address |
| begBal | the beginning balance of the asset prior to the transaction | int256 |
| amountNet | totalIn - totalOut (calculated) | int256 |
| endBal | the on-chain balance of the asset (see notes about intra-block reconciliations) | int256 |
| reconciliationType | one of regular, prevDiff-same, same-nextDiff, or same-same. Appended with eth or token (calculated) | string |
| reconciled | true if endBal === endBalCalc and begBal === prevBal. false otherwise. (calculated) | bool |
| totalIn | the sum of the following In fields (calculated) | int256 |
| amountIn | the top-level value of the incoming transfer for the accountedFor address | int256 |
| internalIn | the internal value of the incoming transfer for the accountedFor address | int256 |
| selfDestructIn | the incoming value of a self-destruct if recipient is the accountedFor address | int256 |
| minerBaseRewardIn | the base fee reward if the miner is the accountedFor address | int256 |
| minerNephewRewardIn | the nephew reward if the miner is the accountedFor address | int256 |
| minerTxFeeIn | the transaction fee reward if the miner is the accountedFor address | int256 |
| minerUncleRewardIn | the uncle reward if the miner who won the uncle block is the accountedFor address | int256 |
| correctingIn | for unreconciled token transfers only, the incoming amount needed to correct the transfer so it balances | int256 |
| prefundIn | at block zero (0) only, the amount of genesis income for the accountedFor address | int256 |
| totalOut | the sum of the following Out fields (calculated) | int256 |
| amountOut | the amount (in units of the asset) of regular outflow during this transaction | int256 |
| internalOut | the value of any internal value transfers out of the accountedFor account | int256 |
| correctingOut | for unreconciled token transfers only, the outgoing amount needed to correct the transfer so it balances | int256 |
| selfDestructOut | the value of the self-destructed value out if the accountedFor address was self-destructed | int256 |
| gasOut | if the transaction's original sender is the accountedFor address, the amount of gas expended | int256 |
| totalOutLessGas | totalOut - gasOut (calculated) | int256 |
| prevBal | the account balance for the given asset for the previous reconciliation | int256 |
| begBalDiff | difference between expected beginning balance and balance at last reconciliation, if non-zero, the reconciliation failed (calculated) | int256 |
| endBalDiff | endBal - endBalCalc, if non-zero, the reconciliation failed (calculated) | int256 |
| endBalCalc | begBal + amountNet (calculated) | int256 |
| correctingReason | the reason for the correcting entries, if any | string |
AppearanceTable
The appearanceTable data model carries an address and all appearances for that address found in any given chunk.
The following commands produce and manage AppearanceTables:
AppearanceTables consist of the following fields:
| Field | Description | Type |
|---|---|---|
| AddressRecord | the address record for these appearances | AddrRecord |
| Appearances | all the appearances for this address | AppRecord[] |
Base types
This documentation mentions the following basic data types.
| Type | Description | Notes |
|---|---|---|
| address | an '0x'-prefixed 20-byte hex string | lowercase |
| blknum | an alias for a uint64 | |
| bool | either true, false, 1, or 0 | |
| datetime | a JSON formatted date | as a string |
| hash | an '0x'-prefixed 32-byte hex string | lowercase |
| int256 | a signed big number | as a string |
| int64 | a 64-bit signed integer | |
| lognum | an alias for a uint64 | |
| string | a normal character string | |
| timestamp | a 64-bit unsigned integer | Unix timestamp |
| txnum | an alias for a uint64 | |
| uint32 | a 32-bit unsigned integer | |
| uint64 | a 64-bit unsigned integer | |
| value | an alias for a 64-bit unsigned integer |
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Chain data
The following data structures describe the output of various TrueBlocks blockchain queries. These data structures basically mimic the data available directly from the RPC.
Each data structure is created by one or more tools which are detailed below.
Block
chifra blocks returns top level data specified block. You can also include an array for the
blocks' transactions.
The following commands produce and manage Blocks:
Blocks consist of the following fields:
| Field | Description | Type |
|---|---|---|
| gasLimit | the system-wide maximum amount of gas permitted in this block | gas |
| hash | the hash of the current block | hash |
| blockNumber | the number of the block | blknum |
| parentHash | hash of previous block | hash |
| miner | address of block's winning miner | address |
| difficulty | the computational difficulty at this block | value |
| timestamp | the Unix timestamp of the object | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| transactions | a possibly empty array of transactions | Transaction[] |
| baseFeePerGas | the base fee for this block | gas |
| uncles | a possibly empty array of uncle hashes | hash[] |
| withdrawals | a possibly empty array of withdrawals (post Shanghai) | Withdrawal[] |
Transaction
Transactions represent eth transfers to and from other addresses.
Most of the fields that TrueBlocks returns are standard to all eth transaction. However, one field
is very interesting: articulatedTx provides a human readable output of the input field.
This is a very powerful way to understand the story behind a smart contract.
The following commands produce and manage Transactions:
Transactions consist of the following fields:
| Field | Description | Type |
|---|---|---|
| hash | the hash of the transaction | hash |
| blockHash | the hash of the block containing this transaction | hash |
| blockNumber | the number of the block | blknum |
| transactionIndex | the zero-indexed position of the transaction in the block | txnum |
| nonce | sequence number of the transactions sent by the sender | value |
| timestamp | the Unix timestamp of the object | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| from | address from which the transaction was sent | address |
| to | address to which the transaction was sent | address |
| value | the amount of wei sent with this transactions | wei |
| ether | if --ether is specified, the value in ether (calculated) | ether |
| gas | the maximum number of gas allowed for this transaction | gas |
| gasPrice | the number of wei per unit of gas the sender is willing to spend | gas |
| input | byte data either containing a message or funcational data for a smart contracts. See the --articulate | bytes |
| receipt | Receipt | |
| statements | array of reconciliations (calculated) | Statement[] |
| articulatedTx | Function | |
| hasToken | true if the transaction is token related, false otherwise | bool |
| isError | true if the transaction ended in error, false otherwise | bool |
| compressedTx | truncated, more readable version of the articulation (calculated) | string |
Withdrawal
withdrawals is an array present in post-Shanghai blocks representing Consensys layer staking reward withdrawals. Note that the amount present is in Gwei. The withdrawals array is not present in pre-Shanghai blocks.
The following commands produce and manage Withdrawals:
Withdrawals consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the recipient for the withdrawn ether | address |
| amount | a nonzero amount of ether given in gwei (1e9 wei) | wei |
| ether | if --ether is specified, the amount in ether (calculated) | ether |
| blockNumber | the number of this block | blknum |
| index | a monotonically increasing zero-based index that increments by 1 per withdrawal to uniquely identify each withdrawal | value |
| timestamp | the timestamp for this block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| validatorIndex | the validator_index of the validator on the consensus layer the withdrawal corresponds to | value |
Receipt
Receipts record the amount of gas used for a transaction among other things. If the transaction succeeded, a receipt might also have logs.
If the to address of a transaction is 0x0, the input data is considered to be the source
code (byte code) of a smart contract. In this case, if the creation of the contract succeeds,
the contractAddress field of the receipt carries the address of the newly created contract.
The following commands produce and manage Receipts:
Receipts consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockHash | hash | |
| blockNumber | blknum | |
| contractAddress | the address of the newly created contract, if any | address |
| gasUsed | the amount of gas actually used by the transaction | gas |
| isError | bool | |
| logs | a possibly empty array of logs | Log[] |
| status | 1 on transaction suceess, null if tx preceeds Byzantium, 0 otherwise | value |
| transactionHash | hash | |
| transactionIndex | txnum |
Log
Logs appear in a possibly empty array in the transaction's receipt. They are only created if the
underlying transaction suceeded. In the case where the transaction failed, no logs will appear in
the receipt. Logs are only ever generated during transactions whose to address is a smart
contract.
The following commands produce and manage Logs:
Logs consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the number of the block | blknum |
| transactionIndex | the zero-indexed position of the transaction in the block | txnum |
| logIndex | the zero-indexed position of this log relative to the block | lognum |
| timestamp | the timestamp of the block this log appears in | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| address | the smart contract that emitted this log | address |
| topics | the first topic hashes event signature of the log, up to 3 additional index parameters may appear | topic[] |
| data | any remaining un-indexed parameters to the event | bytes |
| transactionHash | the hash of the transction | hash |
| blockHash | the hash of the block | hash |
| articulatedLog | a human-readable version of the topic and data fields | Function |
| compressedLog | a truncated, more readable version of the articulation (calculated) | string |
Trace
The deepest layer of the Ethereum data is the trace. Every transaction has at least one trace which
is itself a record of the transaction. If the to address of the transaction is a smart contract,
other traces may appear, if, for example, that smart contract calls other smart contracts.
Traces may be arbitrarily deep (up to the gasLimit) and ultimately represent a tree of function
calls. Some transactions have 100s of traces. The format of the trace is similar to the transaction
itself have a trace action (which contains from, to, value like the transaction) and the
trace result (containing gasUsed like the receipt).
The following commands produce and manage Traces:
Traces consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockHash | the hash of the block containing this trace | hash |
| blockNumber | the number of the block | blknum |
| timestamp | the timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| transactionHash | the transaction's hash containing this trace | hash |
| transactionIndex | the zero-indexed position of the transaction in the block | txnum |
| traceAddress | a particular trace's address in the trace tree | uint64[] |
| subtraces | the number of children traces that the trace hash | uint64 |
| type | the type of the trace | string |
| action | the trace action for this trace | TraceAction |
| result | the trace result of this trace | TraceResult |
| articulatedTrace | human readable version of the trace action input data | Function |
| compressedTrace | a compressed string version of the articulated trace (calculated) | string |
Notes
Traces and TraceActions, when produced during a self-destruct, export different fields when rendered in JSON. In CSV and TXT output, these fields change thier meaning while retaining the header of the original fields. The following table describes these differences:
Fields that change during self-destruct transaction:
| Field | When rendered in JSON | When rendered in csv/txt |
|---|---|---|
| Action.From | Action.Address | |
| Action::To | Action.RefundAddress | |
| Action::Value | Action.Balance | |
| Action.RefundAddress | ||
| Action.Balance |
TraceAction
Other than the first trace which is the trace of the transaction itself, traces represent calls
into smart contracts. Because of this, trace actions closely resemble the fields of the
transaction.
The following commands produce and manage TraceActions:
TraceActions consist of the following fields:
| Field | Description | Type |
|---|---|---|
| from | address from which the trace was sent | address |
| to | address to which the trace was sent | address |
| gas | the maximum number of gas allowed for this trace | gas |
| input | an encoded version of the function call | bytes |
| callType | the type of call | string |
| refundAddress | if the call type is self-destruct, the address to which the refund is sent | address |
| rewardType | the type of reward | string |
| value | the value (in wei) of this trace action | wei |
| ether | if --ether is specified, the value in ether (calculated) | ether |
| selfDestructed | true if the contract self-destructed, false otherwise | address |
| balance | if self-destructed, the balance of the contract at that time | wei |
| balanceEth | if --ether is specified, the balance in ether (calculated) | ether |
TraceResult
As mentioned above, other than the first trace, traces represent calls into other smart contracts. Because of this, the trace results closely resembles the fields of the receipt.
The following commands produce and manage TraceResults:
TraceResults consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | address of new contract, if any | address |
| code | if this trace is creating a new smart contract, the byte code of that contract | bytes |
| gasUsed | the amount of gas used by this trace | gas |
| output | the result of the call of this trace | bytes |
TraceCount
chifra trace --count returns the number of traces the given transaction.
The following commands produce and manage TraceCounts:
TraceCounts consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the block number | blknum |
| transactionIndex | the transaction index | txnum |
| transactionHash | the transaction's hash | hash |
| timestamp | the timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| tracesCnt | the number of traces in the transaction | uint64 |
TraceFilter
The traceFilter is an internal data structure used to query using the chifra traces --filter command. Its use may, in the future, be expanded for other use cases. Note that all fields are optional, but not all may be empty at the same time.
The following commands produce and manage TraceFilters:
TraceFilters consist of the following fields:
| Field | Description | Type |
|---|---|---|
| fromBlock | the first block to include in the queried list of traces. | blknum |
| toBlock | the last block to include in the queried list of traces. | blknum |
| fromAddress | if included, only traces from this address will be included. | address |
| toAddress | if included, only traces to this address will be included. | address |
| after | only traces after this many traces are included. | uint64 |
| count | only this many traces are included. | uint64 |
BlockCount
chifra blocks --count returns the number of various types of data in a block. For example, transactionCnt is the number of transactions in the block, and so on.
The following commands produce and manage BlockCounts:
BlockCounts consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the block's block number | blknum |
| timestamp | the timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| transactionsCnt | the number transactions in the block | uint64 |
| unclesCnt | the number of uncles in the block | uint64 |
| logsCnt | the number of logs in the block | uint64 |
| tracesCnt | the number of traces in the block | uint64 |
| withdrawalsCnt | the number of withdrawals in the block | uint64 |
| addressCnt | the number of address appearances in the block | uint64 |
NamedBlock
Left to its own devices, the blockchain would try to convince us that only hashes and bytes are
important, but being human beings we know that this is not true. TrueBlocks articulates various
types of data with chifra names detailing the names for
addresses, -articulate describing the Functions and Events of a transaction, and
chifra when describing dated blocks. Dated blocks assign a
human-readable date to blocks given block numbers or timestamps and vice versa.
The following commands produce and manage NamedBlocks:
NamedBlocks consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the number of the block | blknum |
| timestamp | the Unix timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| name | an optional name for the block | string |
| description | an optional description of the block | string |
Timestamp
Shows the blockNumber, timestamp and difference in seconds between blocks found in the timestamp database.
The following commands produce and manage Timestamps:
Timestamps consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the number of the block | blknum |
| timestamp | the Unix timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| diff | the number of seconds since the last block | int64 |
LightBlock
chifra blocks --hashes returns top level data specified block with only
the hashes of the block's transactions.
The following commands produce and manage LightBlocks:
LightBlocks consist of the following fields:
| Field | Description | Type |
|---|---|---|
| gasLimit | the system-wide maximum amount of gas permitted in this block | gas |
| hash | the hash of the current block | hash |
| blockNumber | the number of the block | blknum |
| parentHash | hash of previous block | hash |
| miner | address of block's winning miner | address |
| difficulty | the computational difficulty at this block | value |
| timestamp | the Unix timestamp of the object | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| transactions | a possibly empty array of transaction hashes | string[] |
| baseFeePerGas | the base fee for this block | gas |
| uncles | a possibly empty array of uncle hashes | hash[] |
| withdrawals | a possibly empty array of withdrawals (post Shanghai) | Withdrawal[] |
Base types
This documentation mentions the following basic data types.
| Type | Description | Notes |
|---|---|---|
| address | an '0x'-prefixed 20-byte hex string | lowercase |
| blknum | an alias for a uint64 | |
| bool | either true, false, 1, or 0 | |
| bytes | an arbitrarily long string of bytes | |
| datetime | a JSON formatted date | as a string |
| ether | a big number float | as a string |
| gas | a 64-bit unsigned integer | |
| hash | an '0x'-prefixed 32-byte hex string | lowercase |
| int64 | a 64-bit signed integer | |
| lognum | an alias for a uint64 | |
| string | a normal character string | |
| timestamp | a 64-bit unsigned integer | Unix timestamp |
| topic | an '0x'-prefixed 32-byte hex string | lowercase |
| txnum | an alias for a uint64 | |
| uint256 | a 256-bit unsigned integer | |
| uint64 | a 64-bit unsigned integer | |
| value | an alias for a 64-bit unsigned integer | |
| wei | an unsigned big number | as a string |
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Chain state
The data structures produced by tools in the Chain State category provide details on the balances
(ERC20 or ETH) of an address against a particular token or block. Additionally, direct access to
a smart contract's state may be queries with the chirfa state tool. Data structures in that case
are specific to the particular smart contract.
Each data structure is created by one or more tools which are detailed below.
State
For the chifra state --call tool, the result is the result returned by the call to the smart
contract. This is the decoded output value of the smart contract call.
The following commands produce and manage States:
States consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the block number at which this call was made | blknum |
| timestamp | the timestamp of the block for this call | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| address | the address of contract being called | address |
| accountType | the type of account at the given block | string |
| balance | the balance of the account at the given block | wei |
| ether | if --ether is specified, the balance in ether (calculated) | ether |
| code | the code of the account | string |
| deployed | for smart contracts only, the block number at which the contract was deployed | blknum |
| nonce | the nonce of the account at the given block | value |
| proxy | the proxy address of the account at the given block | address |
Token
The token data model represents the name, decmials, token symbol, and optionally the totalSupply
of an ERC-20 token.
The following commands produce and manage Tokens:
Tokens consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the block at which the report is made | blknum |
| transactionIndex | the transaction index (if applicable) at which the report is made | txnum |
| timestamp | the timestamp of the block | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| totalSupply | the total supply of the token contract | int256 |
| address | the address of the token contract | address |
| holder | the holder address for which we are reporting | address |
| priorBalance | the holder's asset balance at its prior appearance | int256 |
| balance | the holder's asset balance at the given block height | int256 |
| balanceDec | the holder's asset balance (in Ether) at the given block height (calculated) | float64 |
| diff | the difference, if any, between the prior and current balance (calculated) | int256 |
| name | the name of the token contract, if available | string |
| symbol | the symbol of the token contract | string |
| decimals | the number of decimals for the token contract | uint64 |
| type | the type of token (ERC20 or ERC721) or none | TokenType |
Result
For the chifra state --call tool, the result is the result returned by the call to the smart
contract. This is the decoded output value of the smart contract call.
The following commands produce and manage Results:
Results consist of the following fields:
| Field | Description | Type |
|---|---|---|
| blockNumber | the block number at which this call was made | blknum |
| timestamp | the timestamp of the block for this call | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| address | the address of contract being called | address |
| name | the name of the function call | string |
| encoding | the encoding for the function call | string |
| signature | the canonical signature of the interface | string |
| encodedArguments | the bytes data following the encoding of the call | string |
| articulatedOut | the result of the call articulated as other models | Function |
Base types
This documentation mentions the following basic data types.
| Type | Description | Notes |
|---|---|---|
| address | an '0x'-prefixed 20-byte hex string | lowercase |
| blknum | an alias for a uint64 | |
| datetime | a JSON formatted date | as a string |
| ether | a big number float | as a string |
| float64 | a double precision float | 64 bits |
| int256 | a signed big number | as a string |
| string | a normal character string | |
| timestamp | a 64-bit unsigned integer | Unix timestamp |
| txnum | an alias for a uint64 | |
| uint64 | a 64-bit unsigned integer | |
| value | an alias for a 64-bit unsigned integer | |
| wei | an unsigned big number | as a string |
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Admin
The data models produced by the tools in the Admin category relate to scraping the chain, producing the Unchained Index, and querying the configuration of the system. Additional data related to sharing the indexes via IPFS and pinning the same are also produced by tools in this category.
Each data structure is created by one or more tools which are detailed below.
Status
The status data model is a complex beast. It contains various information including a list of
registered chains, information about many of the internal binary caches maintained by chifra
as well as current status information about the system including version information for both
chifra and the node it's running against.
The following commands produce and manage Status:
Status consist of the following fields:
| Field | Description | Type |
|---|---|---|
| cachePath | the path to the local binary caches | string |
| caches | a collection of information concerning the binary caches | CacheItem[] |
| chain | the current chain | string |
| chainConfig | the path to the chain configuration folder | string |
| clientVersion | the version string as reported by the rpcProvider | string |
| chainId | the path to config files | string |
| hasEsKey | true if an Etherscan key is present | bool |
| hasPinKey | true if a Pinata API key is present | bool |
| indexPath | the path to the local binary indexes | string |
| isApi | true if the server is running in API mode | bool |
| isArchive | true if the rpcProvider is an archive node | bool |
| isTesting | true if the server is running in test mode | bool |
| isTracing | true if the rpcProvider provides Parity traces | bool |
| isScraping | true if the scraper is running | bool |
| networkId | the network id as reported by the rpcProvider | string |
| progress | the progress string of the system | string |
| rootConfig | the path to the root configuration folder | string |
| rpcProvider | the current rpcProvider | string |
| version | the TrueBlocks version string | string |
| chains | a list of available chains in the config file | Chain[] |
Manifest
The Manifest details the portions of the index of appearances which are called ChunkRecords. Each record in the Manifest details the block range represented by the chunk as well as the IPFS hash of the index chunk along with the associated IPFS hash for the Bloom filter of the chunk. The manifest itself is also pushed to IPFS and the IPFS of the hash of the manifest is published periodically to the Unchained Index smart contract.
The following commands produce and manage Manifests:
Manifests consist of the following fields:
| Field | Description | Type |
|---|---|---|
| version | the version string hashed into the chunk data | string |
| chain | the chain to which this manifest belongs | string |
| specification | IPFS cid of the specification | ipfshash |
| chunks | a list of the IPFS hashes of all of the chunks in the unchained index | ChunkRecord[] |
ChunkRecord
The TrueBlocks index scraper periodically creates a chunked portion of the index so that it can be more easily stored in a content-addresable data store such as IPFS. We call these periodically-created chunks ChunkRecords. The format of said item is described here. A pinned chunk is effectively a relational table relating all of the addresses appearing in the chunk with a list of appearances appearing in the chunk.
The following commands produce and manage ChunkRecords:
ChunkRecords consist of the following fields:
| Field | Description | Type |
|---|---|---|
| range | the block range (inclusive) covered by this chunk | blkrange |
| bloomHash | the IPFS hash of the bloom filter at that range | ipfshash |
| indexHash | the IPFS hash of the index chunk at that range | ipfshash |
| bloomSize | the size of the bloom filter in bytes | int64 |
| indexSize | the size of the index portion in bytes | int64 |
| rangeDates | if verbose, the block and timestamp bounds of the chunk (may be null) | RangeDates |
ChunkIndex
The indexchunk data model represents internal information about each Unchained Index index chunk.
It is used mostly interenally to study the characteristics of the Unchained Index.
The following commands produce and manage ChunkIndexes:
ChunkIndexes consist of the following fields:
| Field | Description | Type |
|---|---|---|
| range | the block range (inclusive) covered by this chunk | blkrange |
| magic | an internal use only magic number to indicate file format | string |
| hash | the hash of the specification under which this chunk was generated | hash |
| nAddresses | the number of addresses in this chunk | uint64 |
| nAppearances | the number of appearances in this chunk | uint64 |
| size | the size of the chunk in bytes | uint64 |
| rangeDates | if verbose, the block and timestamp bounds of the chunk (may be null) | RangeDates |
ChunkBloom
The blooms data model represents the bloom filter files that front the Unchained Index index
portions. The information here is mostly for internal use only as it includes the size and number
of the bloom filters present as well as the number of addresses inserted into the bloom. This
information is used to study the characteristics of the Unchained Index.
The following commands produce and manage ChunkBlooms:
ChunkBlooms consist of the following fields:
| Field | Description | Type |
|---|---|---|
| range | the block range (inclusive) covered by this chunk | blkrange |
| magic | an internal use only magic number to indicate file format | string |
| hash | the hash of the specification under which this chunk was generated | hash |
| nBlooms | the number of individual bloom filters in this bloom file | uint64 |
| nInserted | the number of addresses inserted into the bloom file | uint64 |
| size | the size on disc in bytes of this bloom file | uint64 |
| byteWidth | the width of the bloom filter | uint64 |
| rangeDates | if verbose, the block and timestamp bounds of the chunk (may be null) | RangeDates |
ChunkAddress
The addresses data model is produced by chifra chunks and represents the records found in the
addresses table of each Unchained Index chunk. The offset and count fields represent the
location and number of records in the appearances table to which the address table is related.
The following commands produce and manage ChunkAddress:
ChunkAddress consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the address in this record | address |
| range | the block range of the chunk from which this address record was taken | blkrange |
| offset | the offset into the appearance table of the first record for this address | uint64 |
| count | the number of records in teh appearance table for this address | uint64 |
| rangeDates | if verbose, the block and timestamp bounds of the chunk (may be null) | RangeDates |
IpfsPin
ipfsPin represents the date, CID and metadata filename of a single IPFS pinned file.
The following commands produce and manage IpfsPins:
IpfsPins consist of the following fields:
| Field | Description | Type |
|---|---|---|
| cid | the CID of the file | ipfshash |
| datePinned | the date the CID was first created | string |
| status | the status of the file (one of [all | pinned |
| size | the size of the file in bytes | int64 |
| fileName | the metadata name of the pinned file | string |
ChunkStats
The stats data model is produced by chifra chunks and brings together various statistical
information such as average number of addresses in an Unchained Index chunk among other information.
The following commands produce and manage ChunkStats:
ChunkStats consist of the following fields:
| Field | Description | Type |
|---|---|---|
| range | the block range (inclusive) covered by this chunk | blkrange |
| nAddrs | the number of addresses in the chunk | uint64 |
| nApps | the number of appearances in the chunk | uint64 |
| nBlocks | the number of blocks in the chunk | uint64 |
| nBlooms | the number of bloom filters in the chunk's bloom | uint64 |
| recWid | the record width of a single bloom filter | uint64 |
| bloomSz | the size of the bloom filters on disc in bytes | uint64 |
| chunkSz | the size of the chunks on disc in bytes | uint64 |
| addrsPerBlock | the average number of addresses per block | float64 |
| appsPerBlock | the average number of appearances per block | float64 |
| appsPerAddr | the average number of appearances per address | float64 |
| ratio | the ratio of appearances to addresses | float64 |
| rangeDates | if verbose, the block and timestamp bounds of the chunk (may be null) | RangeDates |
MonitorClean
MonitorClean is a report on removing duplicates from monitors.
The following commands produce and manage MonitorCleans:
MonitorCleans consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the address being cleaned | address |
| sizeThen | the number of appearances in the monitor prior to cleaning | int64 |
| sizeNow | the number of appearances in the monitor after cleaning | int64 |
| dups | the number of duplicates removed | int64 |
| staged | true if the address is in the stage, false otherwise | bool |
| removed | true if the address was removed from the stage, false otherwise | bool |
CacheItem
The cacheItem data model is used to display various caches displayed from the chifra config
tool.
The following commands produce and manage CacheItems:
CacheItems consist of the following fields:
| Field | Description | Type |
|---|---|---|
| type | the type of the cache | string |
| items | the individual items in the cache (if --verbose) | any[] |
| lastCached | the date of the most recent item added to the cache | string |
| nFiles | the number of items in the cache | uint64 |
| nFolders | the number of folders holding that many items | uint64 |
| path | the path to the top of the given cache | string |
| sizeInBytes | the size of the cache in bytes | int64 |
ReportCheck
ChunkCheck reports on the results of tests conducted under chifra chunks --check
The following commands produce and manage ReportChecks:
ReportChecks consist of the following fields:
| Field | Description | Type |
|---|---|---|
| result | the result of the check | string |
| visitedCnt | the number of visited items in the cache | uint64 |
| checkedCnt | the number of checks | uint64 |
| skippedCnt | the number of skipped checks | uint64 |
| passedCnt | the number of passed checks | uint64 |
| failedCnt | the number of failed checks | uint64 |
| msgStrings | an array of messages explaining failed checks | string[] |
| reason | the reason for the test | string |
ChunkPin
Reports on the result of the command chifra chunks manifest --pin [--deep].
The following commands produce and manage ChunkPins:
ChunkPins consist of the following fields:
| Field | Description | Type |
|---|---|---|
| version | the version string hashed into the chunk data | string |
| chain | the chain to which this manifest belongs | string |
| timestampHash | IPFS cid of file containing timestamps | ipfshash |
| specHash | IPFS cid of the specification | ipfshash |
| manifestHash | IPFS cid of file containing CIDs for the various chunks | ipfshash |
Chain
The chain data model represents the configured chain data found in the trueBlocks.toml
configuration file.
The following commands produce and manage Chains:
Chains consist of the following fields:
| Field | Description | Type |
|---|---|---|
| chain | the common name of the chain | string |
| chainId | the chain id as reported by the RPC | uint64 |
| symbol | the symbol of the base currency on the chain | string |
| rpcProvider | a valid RPC provider for the chain | string |
| remoteExplorer | a remote explorer for the chain such as Etherscan | string |
| localExplorer | the local explorer for the chain (typically TrueBlocks Explorer) | string |
| ipfsGateway | an IPFS gateway for pinning the index if enabled | string |
RangeDates
The following commands produce and manage RangeDates:
RangeDates consist of the following fields:
| Field | Description | Type |
|---|---|---|
| firstTs | the timestamp of the first block in this range | timestamp |
| firstDate | the first timestamp as a date | datetime |
| lastTs | the timestamp of the most recent block in this range | timestamp |
| lastDate | the last timestamp as a date | datetime |
Base types
This documentation mentions the following basic data types.
| Type | Description | Notes |
|---|---|---|
| address | an '0x'-prefixed 20-byte hex string | lowercase |
| any | any cache item found in the binary cache | |
| blkrange | a pair of nine-digit block numbers | zero padded |
| bool | either true, false, 1, or 0 | |
| datetime | a JSON formatted date | as a string |
| float64 | a double precision float | 64 bits |
| hash | an '0x'-prefixed 32-byte hex string | lowercase |
| int64 | a 64-bit signed integer | |
| ipfshash | a multi-hash produced by IPFS | mixed-case |
| string | a normal character string | |
| timestamp | a 64-bit unsigned integer | Unix timestamp |
| uint64 | a 64-bit unsigned integer |
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Other
The following commands provide useful miscellaneous tools:
chifra explorea quick way to open a blockchain explorer,ethslurpan older tool that lets you call data from Etherscan. (This has issues of centralization and data quality, see explanation in its section).
Note: some of these tools, such as ethslurp, require an Etherscan key. Follow these instructions
to add a key to your config.
Each data structure is created by one or more tools which are detailed below.
Abi
An ABI describes an Application Binary Interface -- in other words, the Function and Event signatures for a given smart contract. Along with Names the use of ABIs goes a very long way towards making your Ethereum data much more understandable.
Similar to names of addresses, ABI files are not available on-chain which means they must be acquired somewhere. Unfortunately, the Ethereum community has not yet understood that Etherscan is not a good place to store this very important information. For this reason, TrueBlocks uses Etherscan to acquire ABI files and therefore one needs to get an Etherscan API key to use this function.
The following commands produce and manage Abis:
Abis consist of the following fields:
| Field | Description | Type |
|---|---|---|
| address | the address for the ABI | address |
| name | the filename of the ABI (likely the smart contract address) | string |
| path | the folder holding the abi file | string |
| fileSize | the size of this file on disc | int64 |
| lastModDate | the last update date of the file | string |
| isKnown | true if this is the ABI for a known smart contract or protocol | bool |
| isEmpty | true if the ABI could not be found (and won't be looked for again) | bool |
| nFunctions | if verbose, the number of functions in the ABI | int64 |
| nEvents | if verbose, the number of events in the ABI | int64 |
| hasConstructor | if verbose and the abi has a constructor, then true, else false | bool |
| hasFallback | if verbose and the abi has a fallback, then true, else false | bool |
| functions | the functions for this address | Function[] |
Notes
See the chifra abis command line for information about getting an Etherscan key.
Function
ABI files are derived from the Solidity source code of a smart contract by extracting the canonical
function and event signatures in a JSON structure. The function signatures are hashed (using
keccak) into four-byte encodings for functions and 32-byte encodings for events. Because the
blockchain only deals with byte data, TrueBlocks needs a way to decode the bytes back into the
human-readable function and event signatures. We call this process --articulate. Most TrueBlocks
commands provide an --articulate option. See the commands themselves for more information.
The following commands produce and manage Functions:
- chifra abis
- chifra export
- chifra transactions
- chifra receipts
- chifra logs
- chifra traces
- chifra state
- chifra slurp
Functions consist of the following fields:
| Field | Description | Type |
|---|---|---|
| name | the name of the interface | string |
| type | the type of the interface, either 'event' or 'function' | string |
| signature | the canonical signature of the interface | string |
| encoding | the signature encoded with keccak | string |
| inputs | the input parameters to the function, if any | Parameter[] |
| outputs | the output parameters to the function, if any | Parameter[] |
Parameter
Parameters are a constituent part of a Function or Event. The
parameters of a function are each individual value passed into the function. Along with the
function's name, the parameter types (once canonicalized) are used to create a function's four
byte signature (or an event's 32-byte signature). Parameters are important to TrueBlocks because
we use them as part of the ABI decoding and the --articulate process to convert the blockchain's
bytes into human-readable text.
The following commands produce and manage Parameters:
- chifra abis
- chifra export
- chifra transactions
- chifra receipts
- chifra logs
- chifra traces
- chifra state
- chifra slurp
Parameters consist of the following fields:
| Field | Description | Type |
|---|---|---|
| type | the type of this parameter | string |
| name | the name of this parameter | string |
| strDefault | the default value of this parameter, if any | string |
| indexed | true if this parameter is indexed | bool |
| internalType | for composite types, the internal type of the parameter | string |
| components | for composite types, the parameters making up the composite | Parameter[] |
Slurp
THIS SHOULD BE ETHERSCAN DATA RELATED, BUT IT'S NOT TIED IN, SO IT DOESN'T DO ANYTHING
The traceFilter is an internal data structure used to query using the chifra traces --filter command. Its use may, in the future, be expanded for other use cases. Note that all fields are optional, but not all may be empty at the same time.
The following commands produce and manage Slurps:
Slurps consist of the following fields:
| Field | Description | Type |
|---|---|---|
| hash | the hash of the transaction | hash |
| blockHash | the hash of the block containing this transaction | hash |
| blockNumber | the number of the block | blknum |
| transactionIndex | the zero-indexed position of the transaction in the block | txnum |
| nonce | sequence number of the transactions sent by the sender | value |
| timestamp | the Unix timestamp of the object | timestamp |
| date | the timestamp as a date (calculated) | datetime |
| from | address from which the transaction was sent | address |
| to | address to which the transaction was sent | address |
| value | the amount of wei sent with this transactions | wei |
| ether | if --ether is specified, the value in ether (calculated) | ether |
| gas | the maximum number of gas allowed for this transaction | gas |
| gasPrice | the number of wei per unit of gas the sender is willing to spend | gas |
| input | byte data either containing a message or funcational data for a smart contracts. See the --articulate | bytes |
| hasToken | true if the transaction is token related, false otherwise | bool |
| articulatedTx | if present, the function that was called in the transaction | Function |
| compressedTx | truncated, more readable version of the articulation (calculated) | string |
| isError | true if the transaction ended in error, false otherwise | bool |
Message
The Message type is used in various places to return information about a command. For example, when using the chifra names --autoname feature in the SDK, a Message type is returned.
The following commands produce and manage Messages:
- chifra blocks
- chifra chunks
- chifra export
- chifra logs
- chifra monitors
- chifra names
- chifra scrape
- chifra state
- chifra traces
- chifra transactions
- chifra when
Messages consist of the following fields:
| Field | Description | Type |
|---|---|---|
| msg | the message | string |
| num | a number if needed | int64 |
Count
Shows the number of timestamps in the timestamps database.
The following commands produce and manage Counts:
Counts consist of the following fields:
| Field | Description | Type |
|---|---|---|
| count | the number of items in the given database | uint64 |
Destination
The following commands produce and manage Destinations:
Destinations consist of the following fields:
| Field | Description | Type |
|---|---|---|
| term | the term used to produce the url | string |
| termType | the type of the term | DestType |
| url | the url produced | string |
| source | the option that produced the url | string |
Base types
This documentation mentions the following basic data types.
| Type | Description | Notes |
|---|---|---|
| address | an '0x'-prefixed 20-byte hex string | lowercase |
| blknum | an alias for a uint64 | |
| bool | either true, false, 1, or 0 | |
| bytes | an arbitrarily long string of bytes | |
| datetime | a JSON formatted date | as a string |
| ether | a big number float | as a string |
| gas | a 64-bit unsigned integer | |
| hash | an '0x'-prefixed 32-byte hex string | lowercase |
| int64 | a 64-bit signed integer | |
| string | a normal character string | |
| timestamp | a 64-bit unsigned integer | Unix timestamp |
| txnum | an alias for a uint64 | |
| uint64 | a 64-bit unsigned integer | |
| value | an alias for a 64-bit unsigned integer | |
| wei | an unsigned big number | as a string |
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
SDKs
SDKs
Chifra serve provides an API interface to the chifra command line. As part of this
functionality, we've written two SDKs for Python and TypeScript to make using the API easier. We welcome
contributions for other SDKs.
The GoLang SDK is different. Unlike the other SDKs, the GoLang SDK does not require you to run the API server. This has very significant performance implications because there is no serialization of the data. In the server case, the code must read the data from the RPC (or the local binary cache), turn it into a JSON string, and send it to the TypeScript or Python SDK.
In the GoLang SDK, the data is in memory ready for use directly from disc. No strinification. This makes the GoLang SDK as fast as it can possbily be.
The two API-releated SDKs are the TypeScript SDK and the Python SDK.
The GoLang SDKs is here GoLang SDK.
Here's the SDKs repo.
GoLang SDK
The GoLang SDK is in alpha.
The best documentation is available here.
Typescript SDK
The TypeScript SDK is pre-alpha. There is no documentation other than the code.
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.
Python SDK
Here's a link to the Python SDK.
Warning: It's in its very early stage.
Copyright (c) 2024, TrueBlocks, LLC. All rights reserved. Generated with goMaker.